Concurrent access to data by multiple users is facilitated
by the use of a shared data buffer for all users of an ALLBASE/SQL
DBEnvironment. Understanding how this buffer is used can clarify
many concurrency issues.
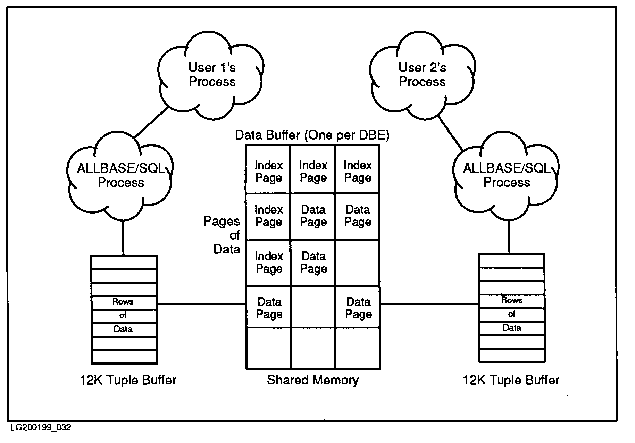
A DBEnvironment running in multiuser mode is accessed by multiple
processes, as shown in Title not available
Figure 5-2 Multiuser DBEnvironment
A single data buffer services the needs
of all users of the DBEnvironment. In addition, each interactive
user or application program has its own 12K tuple buffer associated
with it. The data buffer holds 4096-byte pages from the DBEFiles
in which tables and indexes are stored. All pages of data requested
from tables in the DBEnvironment and all index pages required for
access to the data are read first into this shared data buffer.
In the case of queries, qualifying rows (tuples) are read from the
data buffer into the tuple buffer, and then they are transferred
to the screen (in the case of ISQL) or to host variables or arrays (in
the case of an application program). All changes to existing data
and index pages are placed in the data buffer before being written
to disk.
The use of the data buffer makes access to data efficient,
because pages of data are only read into the buffer when necessary.
These data pages stay in the buffer until they are swapped out when
buffer space is needed for some other page. The use of the buffer
also promotes quick access to the same pages of data by different
transactions, because a page may not have to be read in from disk
if it is already in the buffer.
When you issue a query, you request a specific set of rows
and columns from different tables in a database. The content of
this set of rows and columns is the query result. For every query,
ALLBASE/SQL maintains a cursor, which is
a pointer to a row in the query result. A query result may be much
larger than the size of available memory, so result rows are read
into your application's tuple buffer in blocks of up to 12K at a
time. As your application advances through a query result, the cursor
position advances. When the application has read the last row in
the tuple buffer, a new set of rows is read in until the end of
the query result is reached.
 |
| |
|
 | NOTE: In procedures or embedded SQL applications, you can
explicitly declare and open a cursor for each query result. In ISQL,
you do not explicitly open cursors; ALLBASE/SQL maintains the pointer
position for you. |
|
| |
|
For unsorted queries, the tuple buffer is filled with rows
of data taken from pages found in the data buffer. Of course, the
tuples in the query result are a subset of the content of each data
page. In other words, the data buffer contains everything on each
data page, but the tuple buffer contains only the columns and rows
you have requested. As the cursor moves through the tuple buffer
containing the query result, additional rows must be fetched from the
data buffer. When data has been fetched from all qualifying pages
in the data buffer, additional data pages must be read into the
data buffer from disk, and then additional qualifying rows and columns
must be read into the tuple buffer. In the case of sorting, the sort
output is stored in a temporary table in the SYSTEM DBEFileSet before being read into the data buffer.