|
|
|
|
LU 6.2 API Application Programmer's Reference Manual: HP 3000 MPE/iX Computer Systems > Chapter 1 The SNA Network and LU 6.2 APISystems Network Architecture (SNA) |
|
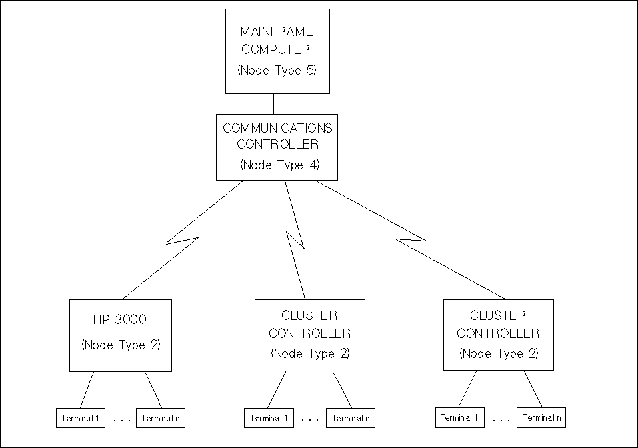
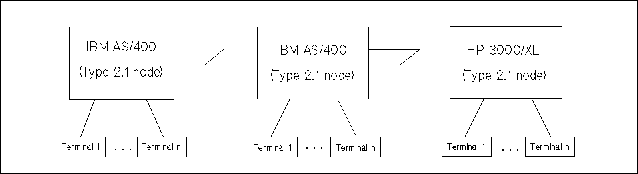
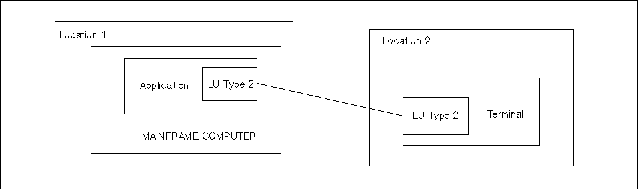
IBM has established a set of protocols that govern communication between various types of machines and applications. This set of protocols is called Systems Network Architecture (SNA). SNA is an architecture designed to be independent of specific software or hardware. In SNA, machines and applications are defined only in terms of the functions they perform. Each machine or node in an SNA network has a node type, which is determined by the set of data communications functions it performs. For example, a Type 5 node is a mainframe or host computer. Any machine that performs the data communication functions defined by SNA for a mainframe computer can act as a Type 5 node in an SNA network. In the past, IBM has focused on centralized data processing, where data is kept in one central location (usually a mainframe computer), and remote processors use the data communication network to access the data. Figure 1-1 “Node Types in an SNA Network” shows a typical IBM network, with a centralized mainframe that serves smaller processors in remote locations. An HP 3000 serves as a remote processor in the IBM environment. At the central location, the mainframe computer and the communications controller work as a unit to send and receive data. The communications controller helps the mainframe manage communication with the remote locations so that the mainframe has more power to process and manage data. A communications controller is a Type 4 node. At each of the remote locations, a cluster controller multiplexes several terminals or other peripheral devices to a single data communication line, making efficient use of the line between the cluster controller and the mainframe. A cluster controller is a Type 2 node. The HP 3000 functions as a Type 2 node. As computers have become smaller and less expensive, companies have replaced cluster controllers with computers like the HP 3000 that adhere to Node Type 2 protocols. Using an HP 3000 as a cluster controller allows a remote location to have local processing power as well as a connection to the mainframe computer. A newer version of the Type 2 node allows remote processors to take advantage of their local processing power and perform more complex data communication functions than traditional Type 2 nodes. This newer node type is called Node Type 2.1, and the older Node Type 2 is now referred to as Node Type 2.0. Type 2.1 nodes, or peer nodes, can establish direct connections between themselves without having to rely on a mainframe or a communications controller to manage data traffic. Communication between Type 2.1 nodes is called peer-to-peer communication. IBM AS/400s function as Type 2.1 nodes. HP 3000s running MPE XL can also function as Type 2.1 nodes. Figure 1-2 “Type 2.1 Nodes in an SNA Network” shows an SNA network without a host node, where two AS/400s and one HP 3000 communicate peer-to-peer as Type 2.1 nodes. A Logical Unit (LU) is the set of data communication functions required by an end user in an SNA network. In SNA, an end user is defined as the ultimate destination of data. So, an end user can be a peripheral device (like a printer or a terminal) or an application program. A Logical Unit is like a port through which an end user sends and receives data. Just as different node types define how machines will communicate, different Logical Unit types define how end users will communicate across the network. Since different peripheral devices use different communication protocols and data formats, SNA assigns an LU type to each kind of peripheral. For example, an LU Type 2 (LU.T2) describes the communication protocols and data format for any terminal that uses the IBM 3270 data stream. Logical Units can communicate only with other Logical Units of the same type. An application on the mainframe that will exchange data with an LU.T2 terminal must have its own Type 2 Logical Unit through which to transmit and receive data. Figure 1-3 “Logical Mapping of LUs” shows a logical mapping between a terminal at a remote location and an application on the mainframe computer. Logical Unit types are usually used for device emulation. LU.T2 devices or applications emulate IBM 3270 terminals, and LU.T1 and LU.T3 devices or applications emulate printers. Logical Unit Type 6.2 differs from other LU types in that it does not emulate a device. LU 6.2 applications exchange raw data in a format called the generalized data stream. LU 6.2 applications can use the generalized data stream to exchange unformatted data, binary data, or data formatted for non-SNA applications and devices. The LU 6.2 architecture defines two kinds of Type 6.2 LUs: dependent LUs and independent LUs.
Communication between LU 6.2 applications is called Advanced Program-to-Program Communication (APPC). APPC and LU 6.2 allow programs or applications running on different processors to communicate and exchange data. When data can be processed at both ends of a communication line, fewer data transfers are necessary to perform certain transactions. If a user must run applications on multiple processors to complete a transaction, a single program on the user's local system can automatically start up the remote applications. The user then has to issue only one command to initiate multiple processes on different computers. The following examples illustrate the advantages of APPC. In the first example, a user at a site without APPC performs a transaction involving applications on the local processor and a remote processor. In the second example, a user performs the same transaction using APPC. A clerk works in a satellite office of a large company. The satellite office receives payments from residents in its local area. Payment information is kept on the local processor for up to three months. Any payment information older than three months is kept at the central office on a mainframe computer. The local processor does not have APPC. A customer comes in who requires payment information for the last six months. The clerk must do the following:
If this is a process that has to be repeated many times during the day, it can become very cumbersome. The clerk must know which information is located on which computer. The clerk must also be able to run two different applications in order to retrieve the information. The following example is the same transaction described above, but the local computer has APPC capabilities, and an APPC application on the local system automates communication with the central mainframe. Now the clerk must perform the following tasks:
The clerk has to run only one application on the local computer, because the local APPC application does the following:
If this is a process that is done repeatedly, and part of the information must remain at the central location, then an APPC application saves a great deal of time. Also, the clerk does not have to know where the data resides in order to run the application. The clerk performs the same steps whether the data resides on the local processor or the central mainframe. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||