 |
by George Stachnik
Welcome to Part 30 of this series
of articles on the HP e3000. For the past several installments,
we've been examining the logic used by application programs to
access the data in IMAGE/SQL databases. As shown in Table 1,
we've discussed many of the intrinsics used to read, write,
and update data in a database. In this article, we're going to
turn our attention to other issues: how to maintain the physical
integrity and the logical integrity of IMAGE/SQL databases.
In order to understand the importance of these concepts, it's
necessary to understand the kinds of corruption that can occur
in a database. IMAGE/SQL itself can (and does) prevent certain
kinds of corruption automatically. This is how it preserves the
physical integrity of the database. The database's structure
depends on its physical integrity being intact. Without physical
integrity, it would be impossible to access the data with predictable
results.
There are other kinds of corruption that can be prevented
only by the application programs themselves. The logical integrity
of the database is maintained when the application programs that
manage the data ensure that it is logically consistent.
Database Structure
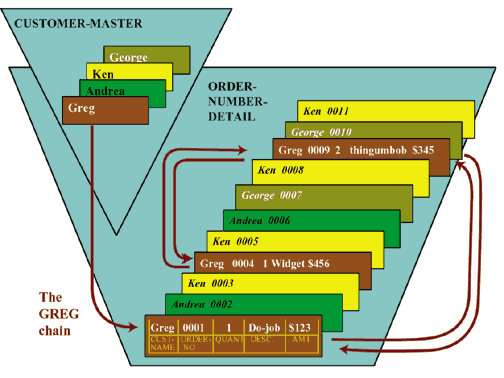
Figure 1 shows the layout
of a sample database that we've been using throughout this series
of articles. The database is made up of two datasets, a manual
master (CUSTOMER-MASTER) and a detail dataset (ORDER-NUMBER-DETAIL).
The layout of the records in the detail dataset is visible at
the bottom of the figure. The figure shows that each record (or
each data-entry, if you prefer the database-specific terminology)
is made up of five fields (or data-items): CUST-NAME, ORDER-NO,
QUANT, DESC, and AMT.
Figure 1: Sample Database
The item called CUST-NAME is the one and only search item
in this database. We can tell (even without having the schema
in front of us) that CUST-NAME is a search item because the master
dataset and the detail dataset share this item.
In order to understand physical integrity, it's important
to understand that each IMAGE/SQL database contains a great deal
of information above and beyond the user data that is stored
there by application programs. IMAGE/SQL also stores a very complex
collection of pointers in each database. These pointers are the
building blocks of the chains that your application programs
use to navigate their way through the data. If those pointers
are inconsistent, then the database loses its physical integrity.
Let's begin by reviewing how IMAGE/SQL maintains chains of
records in a database. Then we'll go on to see what these chains
actually consist of, and learn how IMAGE/SQL guarantees the integrity
of these chains. Figure 1 shows
that for each record in the master dataset there is a corresponding
chain of records in the detail dataset. There are four records
in the master, and each is associated with a customer: Greg,
Andrea, Ken, or George.
For example, three of the records in the detail dataset are
associated with the customer named Greg. These records are organized
in a chain. The chain is represented in the figure by the arrows
that link the Greg records together. You can follow the arrows
to see how the chain of Greg records is built.
Figure 1
also shows that there is a chain of records for each
of the other customers named in the master dataset (although
for simplicity's sake, we've only shown the arrows for the Greg
chain in this figure).
These chains of records are actually constructed of 32-bit
data items called pointers. Each pointer contains the
address of a data entry somewhere in the database. When an application
program uses an IMAGE/SQL intrinsic to retrieve a record from
a database, IMAGE/SQL can often use a pointer to quickly calculate
the virtual address of the record. Pointers enable IMAGE/SQL
to retrieve records very quickly, without having to spend a lot
of time or system resources searching for them.
For example, the Greg record in the master dataset shown in
Figure 1 contains a pointer
to the first Greg record in the detail dataset (the record with
ORDER-NO=0001). When an application program uses DBFIND or DBGET
to retrieve the Greg record from the master dataset, IMAGE/SQL
automatically sets itself up to retrieve the first Greg record
from the detail. No searching will be necessary.
Similarly, each record in the detail dataset contains pointers
to the next record in the chain (if there is one), and to the
previous record in the chain (once again, assuming that one exists).
Each pointer in Figure 1 is represented by an arrow. The
Greg chain begins with the record with ORDER-NO=0001, continues
with ORDER-NO=0009, and ends with ORDER-NO=0004.
When you retrieve a record using DBGET, the intrinsic places
the user data that you requested in a data buffer. This buffer
is one of the parameters that you had to specify when you called
DBGET. But DBGET also retrieves some of the system data (i.e.,
the pointers) from the database. The pointers are placed in the
status array. We discussed the status array in part 25
of this series of articles, but let's briefly review what it
is. The status array is a buffer, made up of an array of 32-bit
data-items. Like the data buffer, the status array must be passed
as a parameter to DBGET. But unlike the data buffer, the same
status array must be passed to each IMAGE/SQL intrinsic that you call.
Figure 2 shows the layout
of in IMAGE/SQL status array in a sample COBOL program. Every
time your program calls an IMAGE/SQL intrinsic, it will pass
the address of this status array to the intrinsic as a parameter.
The IMAGE/SQL intrinsic that you're calling will then pass information
back to the calling program using the status array.
Figure 2: COBOL Definition of the Status Array--Showing the Pointers
002370
002380 01 STATUS-ARRAY.
002390 05 CONDITION-CODE PIC S9(4) COMP.
002400 05 ENTRY-LENGTH PIC S9(4) COMP.
002410 05 RECORD-NUMBER PIC S9(9) COMP.
002420 05 CHAIN-LENGTH PIC S9(9) COMP.
002430 05 BACKWARD-POINTER PIC S9(9) COMP.
002440 05 FORWARD-POINTER PIC S9(9) COMP.
002450
The status array is used chiefly to pass error condition codes
from the intrinsics to the calling programs. In part 25 of this
series, we concerned ourselves chiefly with the first data-item
in the status array, which is where the CONDITION-CODE is located.
We saw that whenever we call an IMAGE-SQL intrinsic, the intrinsic
will return a zero value in the CONDITION-CODE data item if the
intrinsic executed successfully, with no errors. But if something
went wrong, the intrinsic will indicate that there was an error
by placing a non-zero value in the CONDITION-CODE data item.
The calling program can then use the value in CONDITION-CODE
to try to figure out what went wrong.
Whenever you access a record in a database, IMAGE/SQL also
places a great deal of additional information, some of which
can be quite useful, in the status array.
Table 2
contains a brief explanation of each of the data-items
in the status array. In this article, we're going to concern
ourselves with the pointers.
Table 2: Contents of the Status Array
| CONDITION-CODE |
A binary value indicating whether or not the intrinsic call was
successful (A zero value indicates success. A non- zero value indicates
an error.) |
| ENTRY-LENGTH |
The length of the record retrieved |
| RECORD-NUMBER |
The relative record number of the record retrieved in its dataset |
| CHAIN-LENGTH |
The number of records in the chain |
| BACKWARD-POINTER |
The address of the previous record in the chain |
| FORWARD-POINTER |
The address of the next record in the chain |
DBFIND, DBGET, and Pointers in the Status Array
In part 27 of this series, we learned how to use DBFIND and
DBGET to access a chain of records. Let's watch what goes on
in the status array as we use DBFIND and DBGET to walk our way
through the Greg chain illustrated in Figure 1.
Assume that you called DBFIND to locate the Greg chain of
records, and passed it the status array shown in
Figure 2.
When DBFIND returns control to your program, it will
have placed a number of new values in the status array, including
the following:
- CONDITION-CODE now contains a zero (assuming that no errors
were detected by DBFIND).
- The item called CHAIN-LENGTH now contains a value of 3, because
the detail dataset shown in Figure 1
contains three records in the Greg chain.
- FORWARD-POINTER contains the pointer to the first Greg record
in the chain. This is a 32-bit number that IMAGE/SQL can use
to calculate the virtual address of this record, making it very
easy (i.e., fast) to access.
In part 27 of this series, we showed you how an application
program could navigate its way through the Greg chain of records
by following a call to DBFIND with a call to DBGET. At this point,
a call to DBGET that specified chained access (see part 27) would
retrieve the first Greg record from the detail dataset. The status
array is one of the parameters that you must pass to DBGET each
time you call it. This must be the same status array that you
used when you called DBFIND, because DBGET will use the address
that DBFIND stored in FORWARD-POINTER to quickly locate the target
record, i.e., the first record in the Greg chain.
After the call to DBFIND, a subsequent call to DBGET will
retrieve the data shown at the bottom of Figure 1 and
put it in your application program's data buffer. When DBGET
retrieves the first record in the Greg chain, it will also change
the values in the status array:
- CONDITION-CODE will contain a zero (again assuming that no
errors have occurred).
- FORWARD-POINTER will now contain the address of the second
record in the Greg chain. (See Figure 1).
- BACKWARD-POINTER will now contain a zero.
The zero in BACKWARD-POINTER is IMAGE/SQL's way of stating
that "this is the first record in this chain." Because
there is no "previous record," it zeroes that pointer
out. The address in FORWARD-POINTER will point to the record
shown in Figure 1 with ORDER-NO=0009;
this is the second record in the Greg chain.
Now let's suppose that we call DBGET yet again, telling it
to retrieve the next record in the Greg chain. DBGET will use
the address in FORWARD-POINTER to quickly locate the second record
in the Greg chain--the one with ORDER-NO=0009. Upon returning
control to your application program, DBGET will have placed the
second record in the Greg chain in your program's data buffer.
It also will have left its tracks in the status array:
- CONDITION-CODE will once again contain a zero (assuming that
no errors have occurred).
- FORWARD-POINTER will now contain the address of the third
record in the Greg chain. In Figure 1, you can see that
this is the record with ORDER-NO=0004.
- BACKWARD-POINTER will now contain the address of the previous
(first) record in the Greg chain. In Figure 1,
this is the record with ORDER-NO=0001.
In this way, we can use DBGET to walk our way through the
Greg chain, until eventually, there are no more records. Suppose
we call DBGET one more time--retrieving the third (and last)
record in the Greg chain in our program's data buffer. In the
status array, we'd find the following:
- CONDITION-CODE will contain a zero.
- FORWARD-POINTER will now contain a zero, because we're at
the end of the chain. There is no "next" record.
- BACKWARD-POINTER will contain the address of the previous
(i.e., the second) record in the Greg chain.
If we're smart, we can use the zero in FORWARD-POINTER to
deduce that we are now at the end of the chain. There would be
no point in calling DBGET again (at least not using chained access),
because we're at the end of the chain.
In fact, if you did call DBGET again, and told it to retrieve
the "next" record in the chain, DBGET would return
an error. A value of 15 in the CONDITION-CODE is the "end
of chain" error that many IMAGE/SQL application programs
test for when doing chained access.
You can see that IMAGE/SQL uses these pointers as signposts
to allow it to navigate quickly through your database. The network
of pointers can become extremely complex. The database shown
in Figure 1 is very simple--there's
just one master dataset, one detail, and a handful of records.
And yet the twelve records in the detail dataset contain some
24 pointers.
If we were to add a second search item to this database, the
number of pointers in the detail dataset would double. You can
imagine how many pointers would exist in a large database containing
dozens of datasets and millions of records. Maintaining this
labyrinth of pointers is one of the tasks that IMAGE/SQL must
do perfectly--or your databases will quickly become corrupt and
unusable.
Database Corruption
Imagine what would happen if one of these chains were somehow
to become corrupt. What if the forward pointer in the record
with ORDER-NO=0009 (the second record in the Greg chain) were
to change so that instead of pointing to the third Greg record,
it pointed to first record in the Ken chain. Immediately, chaos
would reign. Programs trying to access the Greg chain would suddenly
find themselves accessing data in the Ken chain instead. Subsequent
DBUPDATEs could make matters even worse, writing data that belongs
to one customer into a record made up of data belonging to a
different customer. In very short order, the database (and quite
possibly the business) would be beyond recovery.
If you have been around the HP e3000 for a long time, you
may recall that this kind of corruption used to happen on a fairly
regular basis. The old 16-bit "classic" HP 3000 architecture
contained few safeguards against the corruption of database pointers.
As a result, users of these systems had to protect themselves
against so-called broken chains.
Here's how broken chains happened, and what people had to
do in order to protect themselves against them. Suppose you used
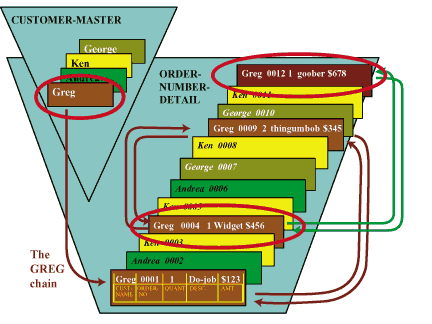
DBPUT to add a fourth record to the Greg chain. Figure 3
shows a database that is very similar to the one we
saw in Figure 1, except for the fact that the Greg chain
now contains a fourth record. IMAGE/SQL has placed the new record
at the end of the Greg chain, and at the end of the dataset.
(This is the most efficient way of doing things, and the way
IMAGE/SQL works, at least by default. If this database had been
designed with sorted chains, the scenario we're about to lay
out would be far worse.)
Figure 3: Second Sample Database
If you're used to file-oriented programming, then you might
be tempted to think that adding a new record to the end of a
dataset would not be any more complex than adding a new record
to the end of a file. But even in this simple scenario, IMAGE/SQL
has to do a lot of extra work. In order to add a record to the
Greg chain, there are a number of other changes that must be
made to the database; three records are affected by the
addition of a new record to the Greg chain. In the very simple
example shown in Figure 3, we've circled the affected
records.
- First of all, we have to write the new record itself. (The
new record appears at the top of the figure, with ORDER-NO=0012.)
This new record is now the last record in the chain. Therefore,
its FORWARD-POINTER will contain a zero. Its BACKWARD-POINTER
will be initialized to contain the address of the record that
used to be the end of the Greg chain.
- Second, we have to update the old end-of-chain record (the
one with ORDER-NO=0004). The FORWARD-POINTER associated with
this record used to contain a zero, but now it must contain
a forward pointer to the new record.
- Third, we have to update the Greg record in the master dataset.
Keep in mind that this record contains the chain-count--the number
of records in the Greg chain. When we add a record to the Greg
chain, this record must also be updated from 3 to 4.
Keep in mind that the database shown in Figure 3
is far simpler than anything you'd be likely to encounter
in the real world. And the more complex a database's structure
is, the more pointers there are, and the more work IMAGE/SQL
must do in order to maintain them. Suppose, for example, that
we changed the database shown in Figure 3
to contain a second search item. In a detail dataset,
each search item is associated with a chain--i.e., with a set
of pointers in each record. When we add a new record to the detail
dataset, it must be added to every chain to which the record
belongs. It's not uncommon for real-world detail datasets to
contain many search items, and therefore many pointers.
These pointer updates are transparent to the application programs
that call IMAGE/SQL intrinsics. All the application program has
to do in order to add a new record to a chain is call DBPUT,
and call it one time only. What we're looking at are the various
things that DBPUT itself must do in order to write the record
to the database and maintain the database's structure and integrity.
Suppose that IMAGE/SQL was in the midst of adding the new
record shown in Figure 3, when
the system crashed because of an error, such as a power failure
or a catastrophic software problem. When the system was restarted,
it would be possible (or even likely) that the pointers would
no longer be consistent. The chain counter might indicate that
the chain contained three records, when in fact it contained
four. Or one of the pointers might point to the wrong record,
or to an address containing no record at all.
These phenomena used to be fairly common on the old classic
HP 3000 systems. They were collectively referred to as broken
chains. With the old 16-bit classic HP 3000 architecture,
system managers had to worry about protecting databases from
the scourge of broken chains. Popular third-party products such
as Adager enjoyed much of their early success because they made
it relatively easy to recover from broken chains after a failure.
When HP brought the 32-bit PA-RISC versions of the HP 3000
to the market in the early 1990s, one of the most important features
of those systems was the integration of transaction management
into the operating system. Transaction management is a feature
of the MPE/iX operating system that makes it possible to group
updates together, and ensure that even in the face of a crash,
either all of the updates happen, or none of them happen.
In Figure 3, we used DBPUT
to add a record to a chain, resulting in updates to three different
records. DBPUT knows that it must make certain that all three
of these updates take place. If for any reason only one or two
of them took place (as might happen if the system were to fail
while the DBPUT intrinsic was executing), the database would
be left in a corrupt state. To prevent this from happening, the
intrinsic groups these changes together into a transaction.
If the system should fail for any reason while a transaction
is being processed, MPE/iX will automatically back out the incomplete
transaction the next time the system is restarted. Transaction
management guarantees the physical integrity of the database,
because it ensures that either all of the records affected
by the transaction are updated, or none of them are updated.
This idea is at the heart of transaction management. MPE/iX
uses transaction management to guarantee the integrity of many
different data structures. IMAGE/SQL databases are protected
by it. So are MPE/iX's internal tables. So is the MPE/iX file
system, which is why you don't need to run a utility like Microsoft's
SCANDISK or UNIX's fsck after a failure on an HP e3000. When
an HP e3000 system is restarted after a failure, MPE/iX's integrated
transaction management will automatically check to see if any
transactions were interrupted by the failure. If so, it will
back out any partially completed transactions that may be on
the system, regardless of whether these transactions were acting
on the file system, on a database, or on some other structure.
Logical Transactions
Because of MPE/iX's integrated transaction management, broken
chains and physical database corruption became a dim memory for
most system managers after the move to PA-RISC. However, there
is another kind of corruption that programmers must continue
to worry about: logical corruption.
Logical corruption of a database happens because of an application
programming error. It is not a condition that can be prevented
by IMAGE/SQL itself. In this and the next couple of articles
we're going to consider two kinds of logical database corruption:
- Corruption due to poor database locking procedures. This
will be discussed in detail next month.
- Corruption due to poor logical transaction management. This
is will form the focus of the remainder of this article.
We've seen that in order to guarantee the physical consistency
of an IMAGE/SQL database, HP invented a feature called transaction
management, which can group together a number of updates to the
database into a transaction. Transaction management guarantees
that either all of the updates happen, or none of them happen.
When designing complex business applications, it's important
to keep the concept of transaction management in mind. In our
simple example, adding an order to the database corresponds neatly
to a single DBPUT, because each order is represented by a single
record in the detail dataset. We don't have to worry about the
addition of an order being interrupted by an error or a system
failure, because IMAGE/SQL will make sure that things are left
in a consistent state.
But in a more complex environment, a single business transaction
such as "adding a part number" or "deleting an
account" might correspond to multiple logical operations.
What if adding a part number to a database involved doing not
just one, but several DBPUTs? Even worse, "adding a part
number" could involve multiple updates to multiple databases
residing on multiple systems on a network.
In such an environment, the likelihood of something going
wrong goes up astronomically. (If 10 systems are involved in
a transaction, then the chances of the transaction being interrupted
by a system failure are 10 times as high as they are when only
one system is involved.)
In the early days of database management, it was comparatively
easy to design applications so that each logical transaction
corresponded neatly with one physical transaction. In other words,
you could design your application so that the logical transaction
of "adding an order" corresponded to one physical
operation, such as a single call to DBPUT. As long as this was
true, you didn't have to worry about logical corruption. But
in today's world of network-driven computing, it's getting more
difficult to design applications in this way.
A number of transaction management products and technologies
have been proposed to protect distributed transactions from failures.
The problem is an enormously complex one, because in order to
be relevant, such a technology would have to be able to manage
transactions on a wide variety of platforms, databases and file
types--each of which offers varying levels of protection at the
physical level.
IMAGE/SQL offers a level of protection for logical transactions.
Suppose you are designing an application in which a business
transaction such as "adding a part number" implies
multiple database operations (multiple DBPUTs, DBDELETEs, or
DBUPDATEs). You need more than MPE's integrated transaction management
in order to keep things consistent. IMAGE/SQL uses MPE's integrated
transaction management to guarantee the physical consistency
of your database against failures, as we have seen. However,
in order for IMAGE/SQL to guarantee the logical integrity
of your database, your application must contain special
logic that defines which database operations are to be grouped
together into transactions.
The old TurboIMAGE DBMS (which was the predecessor of IMAGE/SQL)
contained a facility for defining logical transactions. In TurboIMAGE,
the DBBEGIN and DBEND intrinsics were used to define the scope
of logical business transactions. When an application program
calls the DBBEGIN intrinsic, it is effectively saying, "Here
begins a logical transaction. I am now going to perform a number
of updates to this database (DBPUTs, DBUPDATEs, DBDELETEs, etc.)
followed by a call to DBEND. I am ordering IMAGE/SQL to ensure
that either all of these updates happen, or none of them happen."
DBBEGIN and DBEND act as "bookends" around a logical
database transaction. However, the use of DBBEGIN and DBEND does
not guarantee that incomplete transactions will be automatically
backed out in the event of a system crash. In fact, DBBEGIN and
DBEND have no impact on the database at all. Rather, these intrinsics
write records to a separate IMAGE/SQL log file. We have not discussed
IMAGE/SQL database logging in any detail in this series. For
the moment, suffice it to say that if logging is enabled, every
record that is written to a database is also written to a corresponding
database logfile.
In the event of a failure (including one that involves the
catastrophic loss of the database itself) a program called DBRECOV
can be used together with a backup of the database to manually
recover the database from the logfile. In that case, DBBEGIN
and DBEND records in the logfile will be used to avoid applying
partially completed transactions to the recovered database.
Clearly, this is not an ideal solution. There are a couple
of reasons why. First of all, the overhead associated with doing
IMAGE/SQL logging is significant. The impact on performance may
not be acceptable. Second, if a transaction fails for any reason,
you must do a fullblown database recovery (which can be extremely
time consuming) in order to guarantee the logical consistency
of your database. You must begin with a backup of the database,
and then use DBRECOV to re-apply all the transactions that took
place between the time of the backup and the time of the failure.
In today's computing environments, this is not an acceptable
solution. DBBEGIN and DBEND are primarily supported today in
order to provide backward compatibility for older applications.
They are relics of days gone by.
In the 1990s, HP enhanced IMAGE/SQL with two new intrinsics
called DBXBEGIN and DBXEND. Like DBBEGIN and DBEND, these new
intrinsics are used like bookends to define the beginning and
end of a logical transaction. But unlike the transactions defined
by DBBEGIN and DBEND, these new intrinsics define a so-called
dynamic transaction.
A dynamic transaction is a sequence of IMAGE/SQL intrinsic
calls (DBPUTs, DBUPDATEs, etc.) which alter an IMAGE/SQL database.
When an application program "bookends" a series of
intrinsic calls between calls to DBXBEGIN and DBXEND, MPE/iX's
transaction manager guarantees that either all of these alterations
will be committed to the database, or none of them will.
Dynamic transactions provide a number of useful characteristics.
For one thing, dynamic transactions can be aborted, and partially
completed transactions can be rolled back automatically. Let's
look at an example.
Suppose your application program detects an error while it
is processing a dynamic transaction. Our program has called DBXBEGIN,
and done a series of DBDELETEs to delete a number records from
the database. In order to continue the transaction, the application
intends next to do a series of DBUPDATEs to alter any records
in the database that might reference the ones we just deleted.
Unexpectedly, our program discovers that one of the records it
is supposed to be DBUPDATEing is missing. This is an error condition
which our application should never encounter; the transaction
cannot continue.
At this point, our application program can do one of two things.
First, it can call DBXUNDO. This intrinsic rolls back the active
sequence of IMAGE/SQL intrinsic calls that make up the dynamic
transaction in process. In other words, all the records that
we deleted since we called DBXBEGIN will be automatically restored
to the database. Our brave little application program can then
handle the error however it wants to, and continue processing
the next transaction.
What if, in the programmer's judgement, the error is catastrophic?
In that case, our application program can simply abort itself,
using the standard tools provided in COBOL (or whatever language
it's written in) to terminate abnormally the process that's running
it. In this case, the dynamic transaction in process will be
automatically rolled back. In our example, all the deleted records
will be restored.
DBXBEGIN and DBXEND are a comparatively recent addition to
the HP e3000 programmer's arsenal. They are powerful tools, that
can be used to define logical transactions against a single database
or against multiple databases. If you are maintaining an older
application that predates these tools, you may want to consider
enhancing the application, in order to provide it with protection
from the kinds of failures that can affect the logical integrity
of your data.
Next month, we'll turn our attention to another potential
source of database problems--poor locking strategies.
George Stachnik works in
Hewlett-Packard's Commercial Systems Division in Cupertino, California.
He is responsible for the development and delivery of e3000 training.
|

![[3khat]](/img/3khat16.ico) 3kRanger
3kRanger