←Part 10 Part 12→

The HP 3000--for Complete Novices
Part 11: Software Libraries
by George Stachnik
During the last two months, we've covered some of the basic concepts of program development on the HP 3000. We looked at ways simple programs can be compiled and executed on the HP 3000. Of course, real commercial applications are often far too complex to put into a simple source file like the one we used last month. Instead, they are usually broken up into several subprograms, each of which can be compiled separately, sometimes by different people. Then the pieces are linked together to form the finished application. In this month's article we'll begin examining how this can be done on the HP 3000 using a variety of types of libraries.←Part 10 Part 12→Why Libraries?
In a perfect world, application designers would be able to formulate a single, fixed set of specifications for each application. All through the design, coding, testing, and implementation process these specifications would remain constant. And throughout the life of the application, only small adjustments to the program logic would ever be necessary. The trouble is that none of us live in a perfect world. In the real world, designers don't get to design their applications from scratch. Instead, they are asked to work around existing legacy applications. New applications may even incorporate bits and pieces of existing older applications. Application designers are often forced to work with specifications that represent little more than a best guess at how the software will eventually be used or what it will eventually be asked to do. In the best of all possible worlds, when design specifications changed in response to changes in the business requirements, software developers could go back to square one and start over. But instead of going back to the design, coding, testing, and implementation of the software, they have little choice but to adapt as best they can. The processes that are used to develop software must therefore be made as flexible as possible. The "good old fashioned" way of programming, in which each change in the business takes you back to square 1 to re-spec, recompile, and relink the entire application, may work in a college classroom. But it is simply not practical in today's world (if it ever was practical to begin with). In the future, building new applications from bits and pieces of existing applications may be the best the way to go. The time will come when those older applications will all have been built from objects. They will have been designed to be used and reused. But today, we need to work with the tools and the software that we have at hand. And one of the best (and most underutilized) programming tools is the software library.System Software Libraries
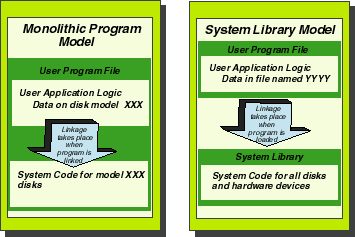
Software libraries are not unique to the HP 3000. There are similar facilities on most versions of UNIX, and on Intel-based operating systems such as MS-DOS or MS Windows. Originally, software libraries were developed to solve a problem in the management of linking user code to system code. Applications programs are made up of two parts: user code, which is written by an application programmer and which is designed to solve some business problem, and system code, which is typically provided by the hardware vendor and which is designed to handle the details of operating the computer. For example, when an application opens a file, the application programmer will code an "open" statement of some kind, (the precise syntax will vary depending on the language being used). The "open" statement is user code. It has to be linked to system code that actually opens the file. This system code contains logic for finding the device on which the file resides, locating the file on that device, and preparing the file to be accessed by the application. In the early days of computing, (prior to the development of the HP 3000) application programs were almost entirely self-contained. When application programs were compiled, the compiler determined which pieces of system code would be required to run the applications. These pieces of system code were linked with the user program. The resultant application program file contained both the system code and user code. The "monolithic program model" depicted on the left side of Figure 1 shows how this used to work. Suppose your program accessed a file. In those days, your user code would include an "open" statement specifying the name of the file, and which kind of disk drive was being used to store the file. The system code for opening, reading, or writing that particular kind of file, was copied into the application program. This system code included hardware-dependent instructions for operating that particular model disk drive. If your computer system contained many application programs, there would be many copies of the system code on your system--one in each application program.Figure 1: Program ModelsThe limitations of this model are fairly obvious. For example, keeping many copies of these system routines (one per application program) meant you could be wasting a fair amount of disk space. (Remember, disk space was a lot more expensive back then.) But this wasn't the biggest drawback. Far more serious was the complexity of managing change. Suppose your hardware vendor brought a new version of the operating system or a new faster disk drive to market. If you wanted to take advantage of the new (presumably less buggy) operating system software or the new (presumably faster and cheaper) hardware, you faced a number of daunting tasks. First of all, you had to install the new drive and copy your files from the old drive. Second, you needed to convert all of your application programs to take advantage of the new device. In the old monolithic program model shown on the left side of Figure 1, applications only "knew" how to use the disk drives that they were "taught" to use when the programs were written. Because the applicable system code was hard-coded into the applications, the applications had to be modified, recompiled, and relinked in order to take advantage of the new system code. Fortunately, things have changed. When you attach a new disk drive to an HP 3000 computer or update to a new release of MPE/iX, your applications do not need to be changed before they can use the new drive. As shown in the "System Library Model" illustrated on the right side of figure 1, system code is not stored in the program file along with the user code. It's stored in a separate file called a system library. But the real strength of system libraries is not so much where the code is stored but when it is linked with your user code. In the "bad old days," the user code and the system code was linked as each application program was compiled and linked. And when the system code changed, the two had to be relinked. But MPE/iX (like all other modern operating systems), links user code and system code when the application is loaded. This takes place whenever anybody executes the application (typically using a :RUN command). The advantage of this is clear. If the system code changes (because you've updated to a new release of MPE/iX or because you've added a new device such as a disk drive to your system), those changes are reflected in the system library. The next time you :RUN your applications, the new system code will automatically be linked with your user code and incorporated into the application that you're running. There's no need to relink your applications every time you make a change to your system.User Software Libraries
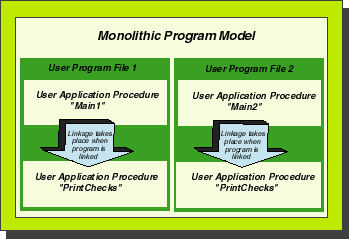
This little history lesson points out why runtime libraries were originally invented. As often happens, however, it turned out that their real value wasn't discovered until after they were invented. People found another use for them. Just as system libraries are used to manage changes in your operating system, people figured out that they could use use runtime software libraries to manage changes in their application environment as well. Most complex application programs are broken up into smaller building blocks called "procedures." On other computer systems, these building blocks may be referred to as "subroutines" or "subprograms" but the fundamental idea is the same. Procedures are defined in the application design process. Each procedure is designed to handle some specific task. Execution of an application begins by executing a "main" procedure. When "main" wants to perform some task, it calls the procedure that was designed and written to handle that task. When the called procedure is finished, it returns control to "main," which picks up at the instruction immediately following the call. Just as libraries make it easier to manage changes in system code, libraries also can be used to manage changes in our procedures. Without libraries, all the procedures that make up an application are linked together into a program file. If any of them are changed, the program file must be relinked. But by putting called procedures in a library, you can put off linking them until execution time. This can save you a lot of work, especially if some of the procedures are shared among multiple applications. Figure 2 shows an example of two simple applications with a shared procedure. Each application is made up of two procedures. The application on the left has a procedure called "Main1" and another called "PrintChecks." The application on the right is also made up of two procedures: "Main2" and "PrintChecks." When the user runs the left-hand program, execution begins with the Main1 procedure. It calls the PrintChecks procedure (probably using a COBOL PERFORM verb) when it's time to print a check.Figure 2: Two Applications with a Shared ProcedureLet's assume that Main1 contains all the logic that is unique to this application program. PrintChecks is a general-purpose procedure (presumably used to print checks of some sort). The figure shows that PrintChecks is shared by two different applications, and in the real world it could be share by many more application programs. To create the applications shown in Figure 2, you'd typically have three source code files--one for Main1, one for Main2, and one for PrintChecks. These three source files would be compiled. The resulting object files would then be linked (using the :LINK command) to create two application programs. If they are linked as shown in Figure 2, a copy of PrintChecks is stored in with the main application logic. By now you should be able to see what some of the potential disadvantages of this model are. Suppose that some change in our business causes us to make a change to the PrintChecks procedure (for example, suppose our company decides to change banks). In the monolithic model shown in Figure 2, any change to PrintChecks would force us to recompile and relink both application program files. This may not seem like a big deal, but if you're trying to manage hundreds or even thousands of programs (as is typical with large complex applications), problems quickly start to arise. Keeping track of applications that use shared procedures can be a very complex job.Resolving Unresolved External References
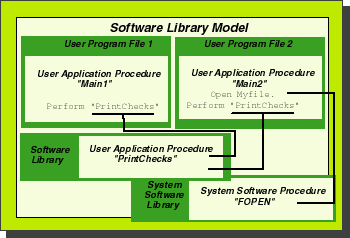
Figure 3 shows the solution, and it's basically just an expanded version of the idea that we used to expedite the sharing of system code. The program file shown in the upper left hand corner now contains only one procedure: Main1. Similarly, the program file in the upper right hand corner now contains only one procedure: Main2. The shared procedure, (PrintChecks) is now stored in a runtime software library. When you run either of the applications at the top of the diagram, they are automatically linked at runtime with whatever shared procedures are needed. This works in exactly the same way that system code is linked with user code. Figure 3 shows a system routine (FOPEN) being linked with one of our application programs.Figure 3: Automatic LinkingLet's take a closer look at how these linkages are done. Whenever an application program is run on the HP 3000, a piece of system software called the loader automatically scans the application for references to other procedures (including both user code and system code) that are not included in the program file itself. An Unresolved External Reference is a piece of software that makes a reference to another piece of software that is not stored in the same file. It's the loader's job to find the software being referenced. There are two unresolved external references to PrintChecks shown in Figure 3--one in each of the two application programs. The shared PrintChecks routine now resides in a Software Library and whenever an application that uses it is :RUN, the loader will locate the PrintChecks routine and link it with the application program. The loader is also responsible for resolving unresolved external references to system software. For example, one of the applications shown in Figure 3 contains a COBOL OPEN statement. The compiler responded to this by generating a call to a routine called FOPEN. FOPEN is a special piece of system code called an intrinsic. Intrinsics are system routines that can be called directly by application programs. For example, the FOPEN intrinsic opens a file for access by an application program. Figure 3 shows the reference to FOPEN being resolved by the loader. (We'll discuss intrinsics in much more detail later in this series of articles). Note that Figure 3 shows two different software libraries--a user library that contains user-written code, and a system library that contains system programs including the intrinsics. Every HP 3000 contains a number of system libraries and a number of user libraries as well. We've seen how runtime libraries help in the management of both operating system and user software. Now that we've established why you'd want to use runtime libraries, we're ready to turn our attention to the question of how you'd use them. That's the subject of next month's article.
George Stachnik, the director of Hewlett-Packard's Technology Closeup series of television broadcasts, holds the title of Chief of Customer Communications. He works at Hewlett-Packard's campus in Cupertino, California.
![[3khat]](/img/3khat16.ico) 3kRanger
3kRanger