A Storage Management Model
For The
HP-UX Enterprise Environment
Marty Ward
VERITAS Software Corporation
1600 Plymouth Street
Mountain View, CA 94043
650-335-8552 (Phone)
650-526-2739 (Fax)
mward@veritas.com
Abstract
In today. s highly complex network computing environments the top priority of IT organizations is to ensure that the company. s essential data is always available. The computing and data storage infrastructure of enterprise computing organizations no longer allows for data . downtime. . With this is mind, it becomes imperative that IT organizations have the most powerful storage management model available, so that their company. s most valuable asset, its data, is managed in the most cost-effective manner and is continuously available.
The goal of this paper is to offer this highly powerful storage management model to empower IT organizations running on the HP-UX platform with the most-efficient and highly available storage management capabilities. This translates into giving end-users continuous data availability at the highest performance possible.
Storage Management Foundation
The model begins, as any project should, with a strong foundation layer, which provides online storage management capabilities that maximize the performance of your storage resources. The foundation layer also ensures high data availability by enabling all storage management operations to be performed online while users maintain continuous access to their data. The foundation layer combines file system and disk management technology to ensure easy management of online storage, optimum performance, and maximum availability of essential data.
In today's distributed client/server environments, users are demanding that databases and other resources be available 24 hours a day, are easy to access and are safe from damage caused by hardware malfunction. Online disk and file system technologies provide easy-to-use online storage management for enterprise computing environments. Traditional storage management is a labor-intensive process often requiring machines to be taken offline - a major (and unnecessary) inconvenience to users. Once the system is offline, the system administrator is faced with the tedious process of backing up existing data, manually changing system parameters, and reloading the data. Having systems offline for any reason is unacceptable to the system administrators and end users.
Storage management foundation technology must integrate tightly with the backup solutions, clustering solutions, and management applications to provide an easy-to-use, scalable storage solution. With an open architecture, these foundational storage solutions can integrate with disk subsystems, databases and 3rd party applications all to ensure essential data and applications are always available.
Storage and data management solutions address the increasing costs of managing mission-critical data and disk resources in enterprise computing and emerging storage area network (SAN) environments. At the heart of these solutions are storage foundation products which provide key benefits and provide the highest possible levels of performance, availability, and manageability for enterprise systems.
A solid storage management foundation provides:
This foundational layer enables return on investment through:
Storage management foundation products are the core technologies needed for superior performance, continuous availability, and easier manageability of enterprise systems and SAN environments. The foundational layer will provide optimal performance turning and sophisticated management capabilities that create a foundation for continuous data availability. Improving the performance of an I/O subsystem results in faster system response times, making systems more available. Easier management reduces error, optimizes system usage, and reduces system downtime. Building your storage foundation layer as discussed will deliver virtually non-stop access to essential data, so customers get the most out of their computing enterprises.
Application Layer
One layer above the foundation is where we begin to specialize based on the needs of the applications. Online transaction processing systems need to have their storage resources tuned differently that a file server application, so this there can exist different storage . personalities. and there are application-specific storage management tools to address all these diverse applications vying for storage within your infrastructure. An in depth discussion on this subject is worthy of a paper all by itself, so to limit the scope (and length) of the topic at hand, we. ll discuss one particular storage application: Databases.
Driven by increasing amounts of production data and a decreasing tolerance for down time, Database Administrators (DBAs) are continually pressed to improve database performance and maintain high availability. The pressure is so great that organizations regularly sacrifice manageability in pursuit of better performance.
The prime example of this trade-off is the decision between running databases on raw partitions or on file systems. File system files are easier to create and manage; there are a host of UNIX file system utilities available for doing so. However, many offer lower performance for database storage.
As a result, DBAs typically use raw partitions to store critical databases requiring high performance and availability. Managing raw partitions introduces a number of difficulties, including restrictive naming conventions, difficulties in growing devices, and more complexity for backup and recovery operations. The DBA. s job is so difficult and yet so necessary that qualified and experienced DBAs are hard to find and retain in-house.
To address the needs of these database environments, this application layer must provide a solution that improves the database environment and simplifies the DBA. s job. The optimum solution would offer DBAs the best of both worlds. the performance of raw disk storage with the manageability of file system-based storage.
The application layer must give DBAs a number of administrative tools that help improve database performance and maintain high availability. For example, a unique block-level incremental backup capability would reduce backup windows to only seconds, even for very large databases. This solution could minimize the system down time and performance degradation that backups incur.
Storage is the heart of a database system. The function of a database is to store, update, and retrieve information in structured ways. The measure of a good database system is the degree to which it can do this with high performance, ease of use, and data integrity.
While good database design is the first obvious way to optimize performance and availability, good storage design is another. Storage is more than the speed and capacity of the storage device; it is also the interaction between the operating system software and the storage device. Intelligent storage software optimizes existing storage devices for the rigorous performance and availability requirements of production databases.
The application layer solution should be well integrated with the storage foundation layer and offer database-specific features for optimal database performance, availability, and manageability such as:
Although the application layer is an integrated storage solution, it should still have a great deal of flexibility to match your specific needs. For example, you can take advantage of the storage management foundation layer to create a highly customized storage configuration, mirroring critical data and striping tablespaces with high update loads.
Raw Disk Performance on File System Storage
In the database world, performance can be everything. Elegant designs fail in production because of performance problems. System administrators spend hours monitoring and balancing I/O loads to achieve better performance.
Performance is the reason many sites use raw partitions for storing databases, despite the difficulties inherent in managing raw partitions. While file systems files are easier to manage than raw partitions, many introduce performance problems when used to store database files. For example:
High performance does not have to come at the expense of manageability. Properly designed, the application layer provides the performance of raw partitions with the manageability of file systems.
The Best of Both Worlds
Managing the increasing demands on database servers is a growing challenge for Database Administrators (DBAs). The Gartner Group predicts that by the year 2000 database sizes will approach 1,000 Terabytes. These large databases will further increase administrative complexity and cost, as well as requirements for high performance and availability. Existing options, like raw devices, do not address the need for manageability, availability, and performance in mission-critical database environments. Raw devices or raw partitions are a great choice for database performance and reliability, but the DBA needs to sacrifice manageability. You need the benefits of both worlds: the performance and data integrity of raw devices and ease of file system administration.
Unique technology in the application layer can present file system files to the database as raw character devices. This technology yields immediate performance benefits:
In addition, this technology can take advantage of asynchronous I/O for further performance improvements by transparently allowing the database to use asynchronous I/O to boost database performance.
These performance improvements alone are sufficient to enable databases files in a file system to achieve the same performance as databases stored in raw partitions, with significantly improved manageability.
For systems with large available memory, this technology can be extended even further to take advantage of additional host server cache. By caching frequently used datafiles, it. s possible to provide up to 140% faster OLTP performance than raw partitions and up to a 300% performance improvement over traditional UFS direct I/O configurations.
Improved Availability through Better Recoverability
Avoiding failures is one component of maintaining high availability; recovering quickly from failures that do occur is just as important. Maintaining consistent and reliable backups is an important part of a DBA. s job. But, the ever-increasing amount of data to back up means that backups take longer to perform and have more of an impact on system performance.
The application layer can provide improved database recoverability by providing specific backup and recovery options tailored for the environment. These options should include:
When a DBA takes a storage checkpoint of a running system, it takes an image of that system at that particular point in time and then tracks the blocks of the database that change from that point forth. Storage checkpoints are very fast to perform and create persistent, disk-based images that can be used for Storage Rollback operations.
Storage Rollback is the process of restoring data to its state as of a specific storage checkpoint. Instead of writing the entire file system from an offline backup, a storage checkpoint only writes back the blocks that have changed to their previous state. This technology provides a very fast recovery option. The DBA can then apply redo logs or archived redo logs to recover the database to the desired point in time.
Used in conjunction with a backup application, the block-level incremental backup technology only writes changed database blocks when performing backup. Block-level incremental backups are extremely fast, which lets administrators perform backups more frequently for better recoverability. This technique reduces the CPU and network resources used during backup and improves data availability by virtually eliminating backup windows.
Application Layer Summary
In a continual quest for improved performance and availability, organizations have placed a significant strain on the DBAs that manage production databases. The DBA. s job is a complex one, managing raw partition devices with limited maintenance windows and complex backup and recovery environments.
Unfortunately, complexity introduces risk . to the organization and to the data. The more complex the task, the greater the chance of error. The expertise required to manage databases has created a large market for experienced DBAs, making it difficult to find and retain qualified individuals for basic ongoing administration tasks.
Application tuned storage technologies can provide proven storage solutions with database-specific agents and extensions to create a software solution that enhances database performance and availability.
Availability Layer 1 . Data backup and migration
Once you have your storage infrastructure tuned to your applications, it. s time to look at the level of availability required by these applications. While both previous layers of the model that we have discussed do offer increased data availability, this layer in particular delves into the detail of just how much is enough. Will they require data backup such that if there is a system outage or data loss the users can get their data restored? Or is the particular application so important that data must be available in seconds if any such system outage occurs? This part of the model offers choices based on the data availability requirements of your system.
The ability to protect all data in the enterprise, from workgroups to enterprise servers is essential. Backup and recovery applications can provide complete data protection for Windows NT, UNIX and NetWare environments (among others). Organizations can manage all aspects of backup and recovery from intuitive, graphical user interfaces, thus allowing consistent backup policies to be set across the enterprise. These applications provides optional database and application specific backup and recovery solutions for Oracle, SAP R/3, Informix, Sybase, Microsoft SQL Server, and Microsoft Exchange Server. "Datacenter" strength media management provides organizations with the ability to perform all aspects of media management, including library sharing. In addition, specialized interfaces can provide complete real-time and historical analysis of all backup and recovery operations.
Scalable Architecture
There are literally hundreds of products on the market performing backup and recovery for open systems environments. However, very few were designed to handle the amount of data in the new data center. Once the sole domain of mainframes, the new data centers are built around large UNIX servers and NT clusters where organizations run their business critical applications.
The datacenter-class solutions offer advanced media management and superior performance. If they best-of-breed solutions, then they likely have a tiered architecture. The first tier consists of a master server concept. The role of the master server is to act as the "brains" for actions such as scheduling and tracking client backups. It can have one or more tape devices/libraries attached for backing up data from multiple clients. If organizations have data in disperse locations or have data intensive applications such as data warehouses, they can implement media servers that provide local backup of large applications while backing up other clients (other servers and/or workstations). A media server can share a tape library with the master server or another media server, or it can operate with its own tape devices/library. If a media server fails, the attached client. s backups can be routed to another media server. The third tier in the architecture is that of the client agents which back up servers and workstations. Normally, this tier represents the largest number of individual machines but not necessarily the most data. Both the media servers and clients can be centrally managed from the master server.
However, for organizations that require centralized management of multiple master servers and/or widely distributed environments, a fourth tier needs to be implemented. This tier offers centralized management and control of all backup storage domains in the enterprise. This allows systems administrators and database administrators to manage all aspects of the backup application. It also facilitates consistent policy management along with the ability to monitor these backup storage domains anywhere in the enterprise.
A storage domain consists of one master server and one or more media servers. In campus situations and where operations may be dispersed in multiple geographic locations, there may be more than one storage domain. One instance of the fourth tier that controls multiple storage domains is called an enterprise domain.
Implementation Flexibility
Both the installation and implementation of any backup/recovery application should be an easy process. In fact, the any Windows version should provide a wizard-driven installation and configuration program. Administrators can define backup schedules with the graphical scheduling interface. The scheduler within the backup application needs to provide the flexibility to define full, incremental and cumulative backups. Flexible scheduling options must also be built in to the scheduler including the ability to not only run backups on a daily/weekly/monthly basis, but also by hour. A backup window can be defined to ensure that backups are not run outside of a predefined window. Lastly, administrators can give backup classes descriptive, multi-word names for tracking and reporting.
Breakthrough Technology
Best-of-breed solutions provide several backup options that redefine traditional backup and restore. One such option allows administrators to perform "snapshot" backups which provide consistent, physical point-in-time backups that incur none of the overhead associated with logical backups. Administrators can also perform logical restores using these "snapshot" backups.
Another breakthrough concept available to database users is block level incremental backup discussed earlier. It negates the need to scan the entire database in order to perform incremental backups, thus greatly reducing elapsed time and resource consumption.
Disaster Recovery
When a disaster occurs, it can be as simple as a disk array crash or as big as the computer room being flooded. Superior backup solutions have not only the ability to perform full or partial recovery from a primary backup, but can be used to recover applications or complete servers in an off-site scenario.
These solutions can provide the ability to automatically create copies of the primary backups. These secondary tapes can then be sent off-site for storage. However, there is more to the story than just copying tapes. First of all, the application "de-multiplexes" tapes so that data is "co-located" on tapes. The reason for this is that most installations have business critical applications that must come up first, followed by secondary and tertiary applications.
The process of performing a selective restore is much faster if the data is co-located. Very rarely does an organization choose to restore a complete server at a hot-site location. Secondly, the backup copies that the application creates should be TAR compatible. While the backup solution may use its own method for moving data and writing data to tape to ensure reliability, it should provide the capability for these tapes to be read by basic UNIX utilities.
For complete disaster recovery automation, the solution should provide an option for complete vault management. This includes everything from ejection of the backup copies to the I/O bin in a tape library to pick/pull reports written in a variety of formats including Arcus and Datasafe. Additionally, tapes can be automatically rotated to and from the off-site vault.
Easy of Use
The definition of an easy-to-use backup and recovery solution has different meanings to different people. Some systems administrators like the control of a command line interface whereas some want 100% graphical user interfaces. Database administrators, on the other hand, want to administer database backup and recovery from the same interface as the systems administrator. The availability layer solution should address all of these issues including multiple choices for administration: Command line, Motif, and Java� based along with a Windows NT Explorer-like interface.
The Complete UNIX and Windows NT Solution
The availability layer solution can provide equal functionality and performance combined with intuitive graphical user interfaces for both UNIX and Windows NT environments. Customers can choose UNIX servers, Windows NT servers or a combination as their backup server platform without sacrificing scalability or ease-of-use.
Hierarchical Storage Management in the Open Market
Hierarchical storage management is for IT organizations who generate an inordinate amount of data that must be retained for extended periods of time and provide user and application access at any time. Data migration can provide easy-to-use, file and data management solutions for Windows NT and UNIX environments and ensures data is secure and always accessible. Unlike alternative options such as the purchase of more disks, which is a temporary fix to management of availability of data, data migration moves older data to cost effective removable media such as tape or optical devices freeing up the space on the servers disk. At the same time, it also allows access to the data at all times thereby increasing primary storage performance and ultimately increasing data availability for all applications and users.
Data migration products increase the availability of critical corporate data by ensuring that only frequently used information is kept permanently online. Infrequently used data is automatically migrated from online devices to lower cost secondary storage such as optical disk or tape. Migrated data is automatically recalled to primary online storage when accessed by users or applications. By reducing the amount of data on disk data migration products improve system backup performance and release disk space for application usage. Recognizing the need for high performance, there are techniques to ensure that migration is transparent and recall is fast, maintaining the levels of service demanded by end users.
Designed for the client server environment data migration is suited to large scale enterprise environments, providing the degree of flexibility required to meet the storage management requirements of these organizations across heterogeneous platforms and providing centralized management capability to aid administration. Data migration forms a critical part of an integrated storage management solution. For example, integration with a backup solution can ensure that migrated data is not recalled just so that it can be backed up and the two products can share a common media management component.
Availability Layer 2 . Clustering and Replication
If data backup and recovery provides sufficient availability for your applications, then the previous section addressed that solution. But if your environment requires the ultimate in data availability then you need to look towards clustering and/or data replication solutions. These storage management solutions can provide levels of data availability that are exponentially higher than traditional backup and recovery solution. The trade-off is of course cost of implementation, but if a company is interested in this level of availability, they have already determined that the cost of not having data available is much greater than the hardware and software solution implementation.
Several major trends are affecting the evolution of enterprise computing architectures. Shrinking budgets and the complexities associated with distributed management are encouraging a re-centralization of critical resources, including servers, storage and management personnel. The availability of ever larger servers (or nodes) and favorable cost factors, particularly in the purchase of storage hardware, are helping to make re-centralization economically feasible. Coupled with the normal growth of storage in a healthy business environment, this consolidation has resulted in an explosive growth of storage capacity that must be managed. This has put new demands on storage management vendors to provide better technologies to share and manage large centralized data stores. As MIS shops evolve to accommodate and leverage these trends, end users continue to clamor for high speed, ubiquitous access to applications and data.
High availability configurations that offer fully automated fault management have become a mainstream technology in the distributed model. Due to the increasing criticality of enterprise data, proactive availability management is becoming a necessity for more and more applications. Re-centralization offers opportunities to improve overall availability management while potentially reducing costs. New architectures, such as storage area networking (SAN), are emerging to supplement existing architectures, offering more choices to improve performance, availability and manageability. Architecture-neutral availability management products must evolve as well to leverage these new architectures, as well as providing the scalability necessary to accommodate the increased size of centralized resource pools. In a more centralized model, availability management products that focus on protecting logically defined application services rather than physical systems will offer a more flexible, more cost-effective approach.
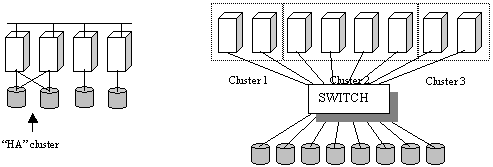
Figure 1. A comparison of the traditional "distributed" data architecture, with a set of shared disk cross coupled between two nodes, with the emerging SAN architecture that supports high speed direct access from any node to any disk.
Storage area networks, in particular, are designed to replace today. s "point to point" (client x accesses node y to get to disk z) access methods with a new "any to any" architecture. In the traditional model, if disks are logically shared, this sharing occurs at LAN speeds (100 Mbit/sec) or is limited to the small number of nodes which can be directly attached to a given disk array (usually no more than four). Through the addition of a high-speed switch, clients can access any disk from any node on the SAN at channel speeds (100MB/sec). This allows a much larger number of nodes much faster access to a much larger centralized data store.
Redundancy is easily added to a SAN through the incorporation of a second switch or redundant switching components to support high availability data access. Additional nodes and disk arrays can be easily added to these configurations with minimal disruption by plugging new components into the switch, providing a much simpler and more scalable growth path than traditional architectures. Finally, multi-node SAN-based clusters offer a much more cost-effective and flexible approach for proactively managing availability at the application level: any node in the SAN may potentially back up any other node. One or two dedicated nodes can now backup a much greater number of nodes, thereby significantly reducing the hardware costs associated with cluster configurations.
Heterogeneity is a reality in today. s enterprise environments. Cost-effective management tools, whether they focus on performance, availability, or some other metric, must offer a wide range of cross platform support. This cross platform support should include various operating system environments, hardware platforms, disk and tape manufacturers and application and interconnect vendors. Products limited to supporting only the equipment of a single vendor will always offer a more expensive and fragmented approach to managing the realities of today. s heterogeneous environments.

Figure 2. Trends driving the emergence of SAN.
Management Needs For The Emerging Storage Architectures
Traditional availability management tools can manage two node clusters reasonably well but are not well suited to manage clusters with more than four nodes. Before the multi-node configurations enabled by SANs can be efficiently leveraged in mainstream enterprise computing, SAN-aware cluster management software must also be available. The appropriate availability management tool will allow various resources, such as physical disks, application services and network connections, to be treated as logical resources. Within the larger, more flexible SAN environments, logical associations between resources can be used to assemble, migrate, recover and manage an application service quickly, easily and in a manner completely transparent to end users. The availability management tool interface should allow for easy access from any platform, offer both a GUI and a command line interface and provide a single point of management for the entire SAN configuration, regardless of the number of clusters.
Basic Concepts In Availability Management
Earlier it was mentioned that to fully leverage larger cluster configurations, an availability management tool needed to focus on proactively managing application services rather than nodes. As nodes get larger, it is less likely that they will be used to host a single application service. Particularly on the larger servers, it is rare that the entire server will be dedicated to a single application service. Failures that affect a single application service, such as a software failure or hang, should not necessarily affect other application services that may reside on the same physical host. If they do, then downtime may be unnecessarily incurred for the other application services.
What Is An Application Service?
An application service is the service the end user perceives when accessing a particular network address. An application service is typically composed of multiple resources, some hardware and some software based, all cooperating together to produce a single service. For example, a database service may be composed of one or more logical network addresses (such as IP), RDBMS software, an underlying file system, a logical volume manager and a set of physical disks being managed by the volume manager. If this service, typically called a service group, needed to be migrated to another node for recovery purposes, all of its resources must migrate together to re-create the service on another node. A single large node may host any number of service groups, each providing a discrete service to networked clients who may or may not know that they physically reside on a single node.
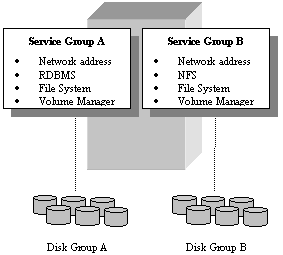
Figure 3. A node hosting two distinct service groups.
Service groups can be proactively managed to maintain service availability through an intelligent availability management tool. Given the ability to test a service group to ensure that it is providing the expected service to networked clients and an ability to automatically start and stop it, such a service group can be made highly available. If multiple service groups are running on a single node, then they must be monitored and managed independently. Independent management allows a service group to be automatically recovered or manually idled (e.g. for administrative or maintenance reasons) without necessarily impacting any of the other service groups running on a node. This is particularly important on the larger server nodes, which may easily be running eight or more applications concurrently. Of course, if the entire server crashes (as opposed to just a software failure or hang), then all the service groups on that node must be recovered elsewhere.
At the most basic level, the fault management process includes monitoring a service group and, when a failure is detected, restarting that service group automatically. This could mean restarting it locally or moving it to another node and then restarting it, as determined by the type of failure incurred. In the case of local restart in response to a fault, the entire service group does not necessarily need to be restarted; perhaps just a single resource within that group may need to be restarted to restore the application service. Application services are typically monitored by a small, application-specific fault management program called an agent. Given that service groups can be independently manipulated, a failed node. s workload can be load balanced across remaining cluster nodes, and potentially failed over successive times (due to consecutive failures over time) without manual intervention, as shown below.
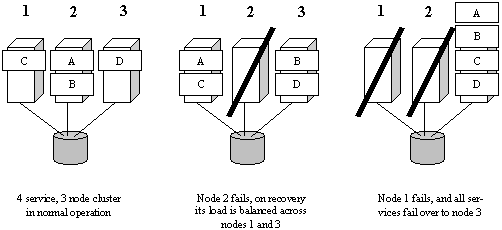
Figure 4. Automated recovery from multiple successive failures, demonstrating dynamic load balancing on failover and "cascading" failover, in a simple three node, shared disk cluster.
Managing Planned And Unplanned Downtime
Application service availability should be measured from a networked clients. point of view. If an application service is unavailable, it does not make much difference to the client that some downtime is planned due to required administrative and maintenance tasks while other downtime is unplanned, due most likely to failures of some kind. Planned maintenance can actually generate a very significant amount of application service downtime as services are taken down to do performance optimization, server expansion or reconfiguration or database or file system backup. A truly comprehensive availability management solution targeted at maximizing application service uptime must offer options to address both planned and unplanned downtime.
What Is Replication?
The term "replication" generally refers to a tool or some combination of tools that is used to automate the process of regularly placing an up to date copy of data from a designated source or primary location to one or more other locations. Typically, the data state on the primary is changing relatively frequently as it reflects user updates. If the data state on the primary did not change very frequently or did not change at all, then it may be acceptable to perform a more labor intensive manual replication process only when needed. When replication needs to be performed on a regular basis, an automated replication tool can reduce the potential for operator error and obtain the most leverage from existing administrative resources.
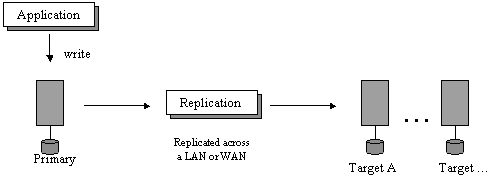
Figure 1. General replication architecture.
Replication Environments
Replication can be used to provide solutions to problems in a variety of application environments. Any application that needs multi-site redundancy or can achieve better performance through geographic distribution can benefit from replication. Multi-site redundancy, where updates to the primary site are immediately reflected at hot remote sites, can be used to effectively address disaster recovery requirements. These availability and/or performance improvements may not be feasible unless replication can be continuous and automated.
In addition, a replication tool can automate data distribution for hot site backups, data vaulting and data migration in specialized environments. For example, replication can be used to logically separate multiple copies of data for disaster recovery, data distribution or continuously update dependent data marts as changes are made to a central data warehouse.
Although businesses may be doing data replication today through a variety of homegrown means, there is no general purpose tool which cost-effectively and robustly automates the replication process. A general purpose data replication tool purchased primarily for use in one application environment may help to pay for itself by its broad applicability in multiple areas. With administrative cycles at a premium, a dependable, general purpose replication tool which is applicable across a wide variety of application environments can minimize operator error and make existing staff significantly more productive.
Key Concepts in Data Replication
There are two methods of operation used in data replication: synchronous and asynchronous.
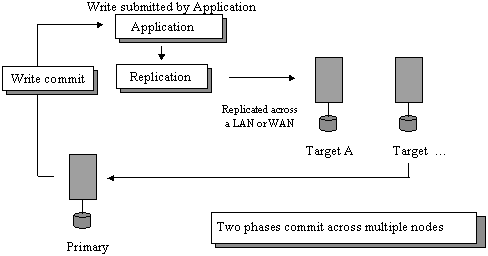
Figure 2. Synchronous replication.
Certain applications or environments require that all servers or sites reflect a given update at exactly the same time. Inconsistent data states, no matter how small, may lead to various exposures and are deemed an unacceptable risk. In cases where this is the primary requirement, the two phase commit protocol used by the synchronous method ensures that a write is not reflected as committed until all participating servers have confirmed that it in fact is committed. There is typically a latency associated with the two phase commit protocol that can degrade application performance. For this reason, synchronous replication is most effectively utilized in application environments with low update rates that require all sites to reflect a common data state at all times. Synchronous replication can trade write performance for better data integrity.
In other applications or environments all servers or sites may not necessarily have to reflect exactly the same data state at all times, as long as they lag by no longer than that period deemed acceptable by the customer. In cases where such a lag is acceptable, asynchronous replication offers better write performance at a designated primary site, but will trade that off against data consistency across sites as well as recoverability. Asynchronous replication allows disparate data states to exist across participating servers, a situation that may result in the loss of transactions in the event of a failure of the primary site. Because of the potential for disparate data states, failure recovery is problematic and requires additional configuration complexity when compared with synchronous environments. Asynchronous replication also requires additional system resources to store changes at a primary site and forward them to all remote locations. Asynchronous replication is most effectively utilized in application environments with high update rates and critical write performance requirements but where the loss of some committed data upon failure is acceptable.
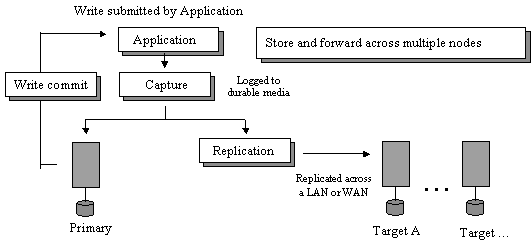
Figure 3. Asynchronous replication.
Replication Summary
Data replication provides a robust, general purpose automated solution designed for use in commercial environments. The replication solution you choose should include synchronous or asynchronous protocol support, where data can be replicated across multiple servers, with all changes reflected and available for use at all participating sites. It is applicable to an environment which requires multi-site redundancy for better availability or geographic distribution for Disaster Recovery. A rich fault management tool set should be included to ensure reliable operation across fault modes, and the solution should be easily customizable to meet individual requirements. Through proper planning, recovery across multiple consecutive failures can be fully automated or require some manual intervention, depending on environment requirement. Replication should require no kernel modifications and be transparent to all applications.
When integrated with the storage foundation layer, a good replication product provides a high performance, highly available, highly reliable and highly manageable general-purpose replication solution applicable to replicated application or disaster recovery environments. Replication technology adds to an established and focused cluster strategy, allowing data integrity and data availability to be of utmost importance in the global mission critical environments of today.
Management Layer
Once the basic layers of the model are in place, the final piece of the puzzle is to make sure this model is being constantly monitored and adapted to meet the changing needs of the enterprise. The top layer of the model discusses enterprise storage resource management tools that allow customers to proactively manage their storage infrastructure. This includes automating reactive management, optimization, and storage planning.
Information, competitiveness, and storage . they go together like never before. In today. s high-paced, information-based, global competitive environment, businesses are faced with many technology challenges, including rapidly-growing distributed systems, exploding volumes of information, de-centralized control of enterprise technology, and reductions in IT staffs and training budgets.
To overcome these challenges, organizations need comprehensive, enterprise-wide solutions. An effective storage management solution must include five essential elements. These five essential elements ensure that a storage management solution will:
The Challenges of Storage Management
Companies all have one common goal - make the best use of the company's information resources to maximize return-on-investment. This means making the best use of storage technology, the linchpin of information availability.
Unfortunately, managing storage in rapidly growing and changing environments makes this goal difficult to achieve. The more distributed systems there are, the more costly the challenge becomes. Gartner Group has estimated that the annual storage management cost for a distributed enterprise with 100 sites is about $4 million.
Managing storage follows the same basic principles of all management . reacting, optimizing, and planning. The difference is that a storage resource failure is likely to have an immediate adverse effect on the business.
Managers of storage resources fix daily problems and if there is any time left, optimize existing technology and plan for future implementations. Effectively maintaining operations enables time to optimize and plan. For most enterprises today, the time spent reacting to daily operations is out of proportion to the other phases of storage management. IT managers can seldom get beyond this reactionary work, resulting in a technology infrastructure with less availability, lower ROI, and frustrated management.
Contributing to the challenge is a plethora of disparate solutions - point products designed for individual storage objects and system-oriented generic frameworks. What is required is centralized control of heterogeneous - decentralized - storage applications that can both maximize availability and minimize operational costs in this complex IT environment.
Lack of Common Approach
Enterprise management of online and offline storage resources means dealing with a patchwork of vendor tools for managing disks, file systems, backups, high availability, and hierarchical storage.
Usually these tools work on differing platforms, in different locations around the world, and are specific to a particular vendor. s storage component. Technology managers are forced to learn a tool for each storage application or system. They must be trained to work with several different interfaces and applications, none of which look or operate the same. The lack of a common storage management approach decreases management effectiveness and increases IT costs since training and administration are in many cases redundant but necessary activities. This approach with a heterogeneous hardware and software environment leads to a management nightmare and a high risk of data loss or availability interruption. According to a June 1997 Gartner Group report, administrative efficiencies are achieved in a dispersed server environment when multiple storage resources can be centrally administered. Centralized storage resource administration provides the ability to define and manage global storage management policies as well as consolidate media management independent of backup storage and control information.
Managing Local and Remote Storage
Management of both local and remote storage in an enterprise environment has become an even more difficult IT challenge, consuming valuable time, money, and resources. The lack of tools to automate the management of heterogeneous storage components means technology managers cannot efficiently manage an enterprise's storage resources. Typically, storage policies and event monitoring happen independently at each site or on each storage object. The more servers, the greater the requirement for additional storage management. This serial method of managing storage resources results in inconsistent storage management and a confusing array of policies across the enterprise. A centralized management application would minimize the number of management resources required to manage each storage object, provide consistent policies, and eliminate the necessity of duplicating and co-locating storage management, increasing efficiencies greatly.
Storage Analysis
Organizations are also faced with the difficult task of trying to analyze how storage affects performance and data availability. Multi-platform tools don. t exist to help accurately configure storage or to predict and correct critical storage problems. It is generally overwhelming to analyze large storage configurations containing gigabytes of data. Many enterprise storage components suffer from poor performance due to storage mis-configurations and uneven distributions of I/O loads. Varying and transient usage patterns can make it difficult to pinpoint these problems. A storage management application could provide the historical data and context to determine optimal configurations.
Planning For the Future
If managing and analyzing present storage resources are a challenge, then intelligently planning for future storage needs can be nearly impossible. Without a way to centrally manage storage-related performance data, there cannot be an accurate, uniform view of current storage capacities or a clear understanding of how long those capacities will last. Technology managers find themselves guessing or reacting when it comes to planning storage capacities - when the current capacities are full or a disaster occurs, it's time to buy more. Centralizing or consolidating storage management enables a proactive approach to planning for future storage. It provides the mechanism and enterprise-wide information to intelligently determine storage needs before they are immediate.
Meeting the Challenge: Storage Management Tools
There exist solutions to the dilemma of managing storage in the enterprise. Implementing a family of storage management tools that consists of integrated products can effectively monitor and manage the local and distributed storage components. This management layer solution enables centralized storage management and consistent storage policy management in addition to the automation of performance, configuration and planning management for the enterprise. The management layer family should be able to do:
Storage Resource Management
Storage resource management provides an end-to-end perspective of all storage objects and applications throughout the enterprise. From a single interface, administrators can monitor the state of storage components such as databases, file systems, logical and physical volumes, tape drives, robotic devices, network connected storage peripherals, backup jobs, and highly available clustered servers. It can automatically alert managers to any problems that occur. It should provide a familiar interface utilizing easy-to-use wizards and menus to set and enforce storage management policies. The interface can include real and historic performance graphing capabilities to determine storage bottlenecks.
Storage resource management should offer policy-based management and enforcement - allowing policies to be set up, automatically monitored and, if desired, automatically corrected, should a breach in policy occur. Storage policies can be set up to monitor data and then react to certain events or conditions. The policies can have actions associated with them to enable execution of any necessary corrections.
Storage resource management is the basis for the other management layer tools. It can be designed to work with third party applications, through the use of autonomous agents. It can help manage all storage resources, and includes the ability to launch the appropriate application in the correct context, directly from the management interface.
Storage Optimization
Storage optimization involves a rules-based, proactive application that analyzes storage object performance and recommends storage parameter changes to improve system performance and reliability. After detecting problems, this tool will recommend configuration and tuning improvements to optimize the enterprise storage management environment for the best performance and the best return-on-investment of resources. Storage optimization is a robust solution for enterprise environments because it has the ability to look at many storage objects simultaneously and make recommendations on the combined system rather than on one isolated storage resource. For example, there may be a question as to why a backup jumps from two hours to four hours overnight. An optimization tool can look at the overall system and determine which storage object was responsible for a sharp increase in the amount of data to be backed up. Or, it could detect that the tape unit was having media problems and could not handle the required throughput.
Management Layer Summary
Efficiently managing a company. s continually changing and elusive storage resources - resources that house and protect the organization. s information - is a vital business element in today. s competitive world. The rapid growth of technology and the dispersion of systems and storage resources throughout the enterprise have created a difficult management challenge. The management layer offers a robust solution to address issues of proactive versus reactive storage management, enabling more productive levels of optimizing and planning. These storage management tools deliver a variety of benefits to the enterprise including:
The management layer ensures that managers will spend less time reacting . trying to determine what storage resources are causing problems. When a problem event occurs, an intelligent, consistent approach to the problem becomes possible, minimizing reactionary, damaging actions. Technology managers can spend more time tuning and optimizing the environment for the current workload, and planning for growth while considering the future workload . optimizing the use of expensive business resources and ensuring availability of business information.