In the new millennium, workers will continue to conduct business in mobile, remote environments. New technologies with flexible, distributed client/server architectures will replace rigid mainframes, reducing time-to-market, increasing productivity and profits. Availability will be synonymous with 24x7 global operations, the Internet and electronic commerce.
Today and into the new millennium, there is no room for downtime.
As companies evaluate their mission-critical computing requirements, they realize that IT is no longer just a technical decision; it also is an investment decision. As with any expenditure, both proactive and reactive mission-critical services to achieve guaranteed uptime must be evaluated in terms of their return on investment (ROI). Mission-critical services mean guaranteed uptime with both high reliability and performance.
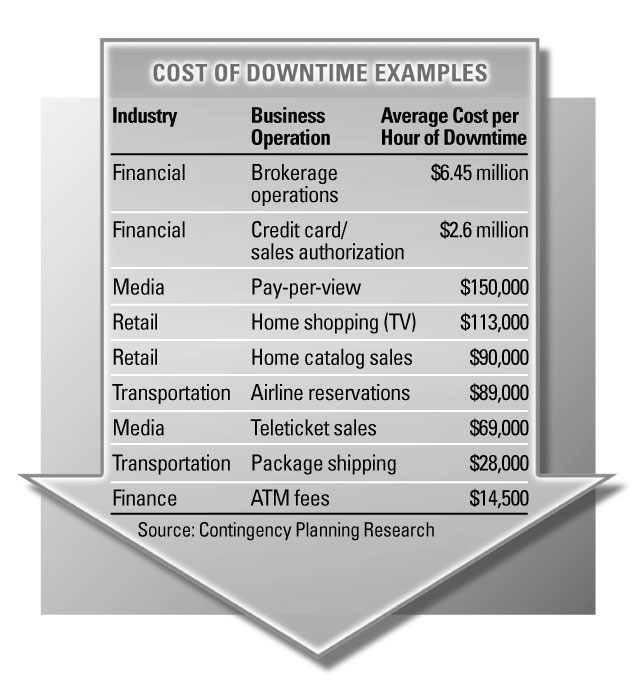
Although the cost of downtime varies by company, the conclusion is the same: Any outage regardless if it is an isolated department, a network or an entire system directly affects user productivity and ultimately revenue. Lost sales or opportunities are the obvious consequences. The actual cost of downtime, however, also includes indirect costs, such as negative publicity, loss of customer satisfaction, overtime pay or loss in stock price. Just consider the scope of some recent outages:
"System Crash Stalls Avis." (Computerworld, 5/18/98) When a major travel reservation system suffered a 31-hour outage caused by a software glitch and an overloaded network, Avis and other travel agency bookings came to a grinding halt during the pre-Memorial Day rush.
"Online Glitch Puts Amazon.com Temporarily out of Business." (San Jose Mercury News, 1/8/98) At the time, Amazon.com, the online bookseller, sold approximately $15,600 books per hour. The Internet site was down for almost 12 hours.
"Computer Problems Hit Schwab Again" (Los Angeles Times, 7/4/97) Last summer, Charles Schwab Corp., the San Francisco-based discount broker, suffered a 6% immediate drop in its stock price when computer problems prevented online trading and access to account information. Schwab was completing an end-of-the-quarter reconciliation. It was the second crash in a week.
For these and many other businesses, the competition is only a click away. In each of these outages, mission-critical services could have helped, if not completely eliminated downtime.
To meet today's challenges of distributed, heterogeneous client/server computing that crosses continents, companies are taking service and support to a new level. Chief information officers want service level agreements (SLAs) that include end-to-end guarantees across the enterprise and through the applications level. These SLAs must measure their effectiveness or success based upon achieving the uptime level agreed upon in advance.
With competitors leapfrogging each other, the only way to get ahead is to be more "available" to customers. As Fed Ex discovered when its competition mastered the ability to "ship any package anywhere, anytime," the company could differentiate its overnight services by providing customers with such conveniences as "point and click" tracking.
Delivering smooth service rests largely on the shoulders of IT managers. Not only must their systems support the growing demands of their business, but their technology needs to run at peak efficiency at all times.
Forced to balance business needs with changing technology, IT managers must meet customer demands with strong support services. From a business viewpoint, rapid growth in transaction volumes, additional needs for large data repositories and continually changing business alliances all put increased pressure on IT to meet customer demands for availability. Correspondingly, the growth of open systems, electronic commerce and the Internet bring additional technology demands that can threaten uptime availability to users.
Today, IT managers want an unmatched level of business confidence, safety and peace of mind. These benefits ultimately will translate into greater IT efficiency, greater end-user satisfaction and increased company profitability.
With the increasing popularity and use of the Internet and intranets, companies are defining disasters differently. In the past, companies were concerned about business or systems recovery after a disaster. Now, the issue revolves more around strategies for staying in business, regardless of what happens.
A study by the University of Texas found that only 6% of companies suffering from a catastrophic data loss survive, while 43% never re-open and 51% close within two years. In a client/server environment, IT stands at the forefront, advocating changes to increase availability. Mission-critical services can increase productivity, control and revenue as well as save time and resources through proactive monitoring and diagnostics.
System availability has come a long way. What once were costly, complicated options to make computing resources accessible are now critical components in day-to-day business activities. From improving productivity, to increasing profitability or enhancing service, businesses large and small, in virtually every industry depend on the availability of their information systems. Consider these examples:
Without mission-critical solutions, many businesses cannot maintain their mission-critical applications, or even survive.
So what is high availability? According to International Data Corporation (IDC): "A system is considered to be highly available if, when failure occurs, data is not lost and the system can recover in a reasonable amount of time."
But just what constitutes "reasonable?" The specifics will differ with each business' requirements and its tolerance for outages. The following hierarchy defines availability in terms of the amount of downtime per occurrence. As customers move up this hierarchy, the time associated with either planned or unplanned downtime decreases and the need for availability increases.

Reliable systems form the baseline for measuring availability. At this level, system interruption is limited to six hours per occurrence plus database recovery. Users must repair failed components, reboot, log on to the system, then restart and recover such applications as the database. Planned maintenance may occur infrequently, typically after operating hours. Occasional downtime, while annoying, is within expectations, provided data integrity is preserved.
Highly resilient systems, the next level in the hierarchy, increase system availability by eliminating single points of failure (SPOF). Service interruption should be limited to 30 minutes per occurrence, excluding database recovery. Users must reboot, log onto the system, then restart and recover applications. Planned maintenance generally is scheduled outside of operational hours and may be rescheduled if required.
Technology infrastructure for highly resilient systems is achieved through enhanced failure recovery, individual component redundancy and/or add-on products (such as disk mirroring or disk arrays) to eliminate single points of failure. IT processes require performance and system monitoring with disciplined IT management processes.
Highly available systems are able to reduce downtime or service interruption to one to five minutes per occurrence (plus database recovery). Infrequent, planned maintenance is completed by moving applications from one system to another. The second system continues to service requests while the original system is updated, thus maximizing availability. Any unplanned downtime event that may affect performance has rapid failover and recovery technology or processes to limit the service interruption to five minutes per event, plus database recovery. At this level of availability, users may need to log on to the system and restart and recover applications.
Technology infrastructure for highly available systems is achieved through multiple, independent computer systems arranged into a networked configuration or cluster. High availability software, such as MC/ServiceGuard, enable the systems to interoperate.
Most highly available systems also include redundant networks. IT processes provide proactive enterprise application and infrastructure monitoring with comprehensive IT service management. Highly available systems also require significant proactive support for all IT processes and restoration commitments.
Continuously available systems, which top the hierarchy, provide 7x24x365 operation, regardless of planned or unplanned downtime. With planned maintenance performed online, the longest service interruption associated with continuously available systems is three to 15 seconds per occurrence. Recovery is fully automated and transparent to users. In fact, the key elements of continuously available systems are transparent recovery and transparent client reconnection to applications.
Continuously available systems require complete system interconnect redundancy. This is achieved through specialized fault tolerant architectures designed for continuous operations. IT processes are characterized by highly stabilized operating environments with comprehensive procedures for automatic IT services, management, monitoring and recovery.
If the goal of mission-critical computing is guaranteed up-time to the customer internal or external the ultimate in tools are integrated environments that can predict outages and begin corrective action before the system starts to go down. In a predictive, self-healing IT world, a person somewhere will be alerted and the component can be fixed or failover procedures started before an outage occurs.
The particular needs of a business and its operating environment will determine a company's approach to availability. A business should begin by identifying key processes and elements within its environment that require mission-critical solutions. If the calculated costs of downtime are high or if downtime affects critical business issues, the company will determine that there is a strong need for comprehensive mission-critical services. The company, however, also must realize that the right technologies, partnerships and right processes are necessary to support a mission-critical environment.
The strength of an IT environment is limited by the strength of its weakest link. If any one component is weak whether it is hardware, the operating system, the network, middleware or applications the solution for the entire enterprise can collapse.
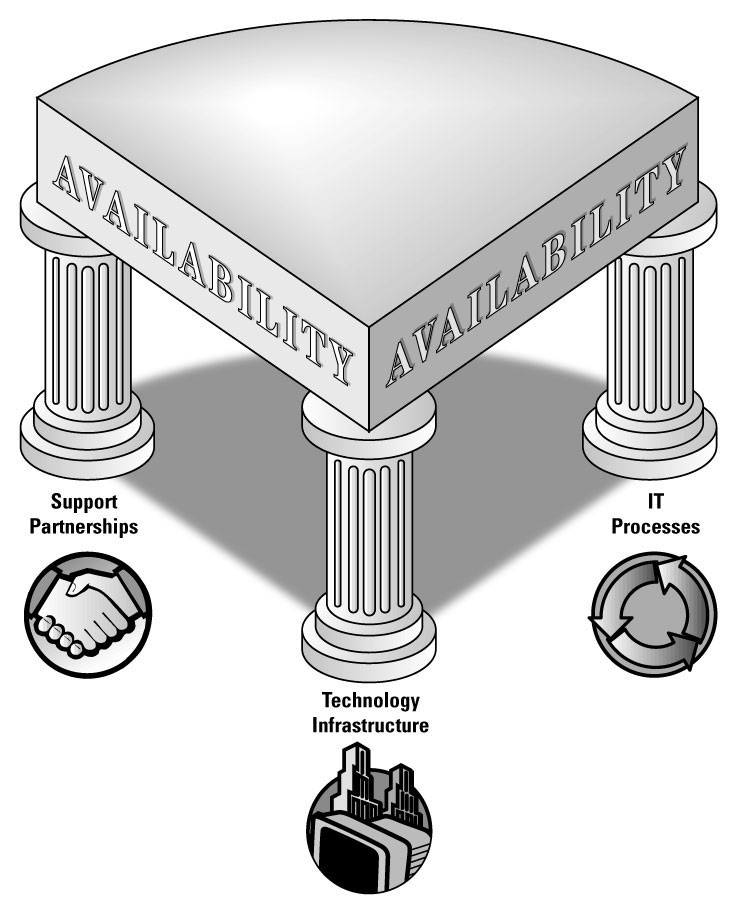
Building effective, highly available systems for decision support requires a strong foundation. There must be a solid infrastructure with efficient IT processes and strong support partnerships. This foundation is supported by three pillars: Technology Infrastructure, IT Processes and Support Partnerships.
First, the technology must be reliable and resilient enough to withstand maximum performance for both internal and external change. Second, an enterprise's systems must be capable of easy, automatic management so that operator error, which can account for between 20% and 40% of all unplanned downtime, will have minimal effect. Third, supportability must be built into the technology. Each pillar supports the different levels of the availability hierarchy.
The first pillar, a reliable and resilient technology infrastructure, applies to all hardware and software. For reliable systems, the technology infrastructure is achieved with mirroring or RAID devices.
For highly resilient systems, the technology infrastructure is achieved through enhanced failure recovery, individual component redundancy, and/or add-on products that eliminate single points of failure. For highly available systems, the technology infrastructure is achieved through multiple independent computer systems arranged into a networked configuration, or clusters, in which the systems interoperate through mission-critical software.
Systems operating at the highest level in the hierarchy, that of continuous availability, require complete interconnect redundancy. Most achieve this through specialized fault tolerant architectures designed for continuous operations.
The second pillar of availability -- easy, automatic IT processes -- includes limited resource monitoring, routine backups and formal IT procedures. Constructing this pillar is often the biggest challenge. If a company does not have in-house people and processes focused on availability and performing the right functions, then even with the best technology in the world, the solution won't be highly available.
To lessen the frequency and impact of operator error, mission-critical systems must be managed effectively. The operating system must be able to monitor and recover key resources, as well as integrate with a complete set of communication protocols. However, proven processes also are important. They can isolate a problem, actively managing its parts and preventing a situation from escalating.
As challenging as it is, effective management can be built with internal processes and proactive support contracts. IT processes include the ability to manage and operate the computing environment as well as implement proactive processes for performance management, configuration management and change management.
IT processes for reliable systems should include resource monitoring, routine backups, change management and configuration management. For highly resilient systems, IT processes should include continual monitoring of system components and performance levels as well as formal processes for change, configuration and problem management.
IT processes for highly available systems must include proactive monitoring of the infrastructure and the applications. The IT Service Management processes should be comprehensive, and include the following processes: build and test; release to production; problem management; operations management; service desk; configuration management; change management; service level management; availability management; and capacity management.
All of the IT Service Management processes should be formalized, and when possible, automated, to support continuously available systems. When possible, recovery procedures also should be automated.
The third pillar supporting availability consists of support partnerships. Supportability encompasses reactive services, predictive capabilities and remote diagnostic tools coupled with training and education. Problems can be diagnosed remotely and resolved faster with the highest level of reactive service, built-in supportability that incorporates the latest technology and a specially trained staff. Reactive efforts are necessary to restore availability in the event of a failure.
The clear objective is to get the system functioning again before solving the technical problem. Predictive capabilities often are designed into the technology. They include such features as online diagnostic tools or diagnostic software that alerts staff to impending failures or to disks that can be swapped or added while the system
The first pillar, a reliable and resilient technology infrastructure, applies to all hardware and software. For reliable systems, the technology infrastructure is achieved with mirroring or RAID devices.
For highly resilient systems, the technology infrastructure is achieved through enhanced failure recovery, individual component redundancy, and/or add-on products that eliminate single points of failure. For highly available systems, the technology infrastructure is achieved through multiple independent computer systems arranged into a networked configuration, or clusters, in which the systems interoperate through mission-critical software.
Systems operating at the highest level in the hierarchy, that of continuous availability, require complete interconnect redundancy. Most achieve this through specialized fault tolerant architectures designed for continuous operations.
The second pillar of availability easy, automatic IT processes includes limited resource monitoring, routine backups and formal IT procedures. Constructing this pillar is often the biggest challenge. If a company does not have in-house people and processes focused on availability and performing the right functions, then even with the best is still online.
The availability of support for different versions of an operating system also should be considered. Because installation of a new version of an operating system requires planned downtime and introduces change, organizations with mission-critical applications may not be quick to upgrade their server operating system. These organizations need to be assured that support will exist for older versions of that operating system and that assistance will continue to be available for planning and deploying upgrade changes.
In seeking mission-critical services, organizations want to establish strong partnerships through strategic alliances. Organizations look for more personal attention. They want a proactive partner who will look out for their interests and who regards the organization's downtime as seriously as if it were its own. The right partner can assist with technology selection and deployment.
A support partnership for reliable systems should include basic preventive maintenance with a standard response. This includes basic telephone response, help desk support and ongoing system and application updates.
To satisfy the support partnership pillar for highly resilient systems, the vendor's time-to-repair commitment should be heightened and proactive risk management should be more personalized.
For highly available systems, redundant networks can be protected with proactive comprehensive IT management. Most highly available systems have Service Level Agreements (SLAs) internally and with vendors. This level requires significant proactive support for all IT processes with restoration commitments. A strong partnership increases the vendor's understanding of the business and allows the vendor to recommend changes to both the IT environment and the processes.
Vendor support for continuously available systems is characterized by extreme escalation procedures, maximum on-site support and service level guarantees. At this level, the vendor also serves as a trusted advisor, making proactive suggestions to help meet organizational goals and improve system availability. The customer relies on the vendor's knowledge of their business strategy to implement new technology and leverage business trends.
As described in the hierarchy and the pillars of availability, a strong foundation is required to build an effective, mission-critical system. First, the technology must be reliable and resilient enough for both internal and external change. Second, the system must be capable of easy, automatic management to minimize the impact of human error. Third, varying levels of support partnerships should be factored into the technology.
Often, however, IT managers seek an objective benchmark of their system's "mission-critical readiness," measured in terms of people, processes, technology and environments. For the benchmark to be meaningful, IT managers need to measure how service partnerships will deliver different levels of availability. They also need to measure how investments will correspond to the availability level achieved.
Hewlett-Packard Company developed the Availability Continuum to establish a standard framework of availability and to clarify its vision and strategy for mission-critical computing. This continuum is a methodology for articulating the levels of availability. It can help customers evaluate their availability requirements, understand the impact of downtime on their businesses and then determine the necessary investments in the three Pillars of Availability technology infrastructure, IT processes and support partnerships to achieve the optimal level of availability.

In short, the goal of the Availability Continuum is to help customers achieve their desired level of system availability and determine the appropriate investment based on the hierarchy and pillars of availability. The continuum compares a company's availability requirements to those of industry analysts. By offering a model, the continuum guides customers on a direct path to understanding the investments required to meet their needs.
The left side of the Availability Continuum assists customers in identifying their availability needs. It presents customers with two considerations. The first is to determine the business impact of a downtime event. The second is to determine how much a business may need to invest to minimize downtime occurrences. Such investments, which may vary throughout the organization, depend upon the applications that are run. Even businesses that claim only a minimal impact from downtime still will suffer minor inconveniences and experience limited costs to recover. A common example of downtime at this low level might be the failure of a file and print server.
By contrast, a business that experiences the maximum impact of downtime would suffer unrecoverable financial loss or an unacceptable interruption of business. Financial loss not only includes lost revenue, but also soft costs such as bad publicity, penalties, litigation or the negative impact on customer satisfaction.
Evaluating the business impact of downtime is the first step to determining the availability requirements for reliable systems, highly resilient systems, highly available systems and continuously available systems. Each level requires different investments in the three Pillars of Availability.
The customer must invest in each pillar to meet specific availability requirements. Investing in only one or two pillars cannot address all the causes of downtime and will not provide the total solution to meet a customer's mission-critical needs.
Mission-critical is not a product that can be purchased. Rather, it is a goal achieved by planning, designing, building, measuring and managing. To maintain and improve systems without disruption requires a strong combination of reliable technology, strong support and flexible, effective management. Before each of these pillars can be constructed, a business must understand where its needs rank in the availability hierarchy. Navigating this road can be circuitous and highly frustrating. Through its Availability Continuum, HP offers a direct route so that customers can reach their destination and use technology to meet their mission-critical IT objectives and business goals.
Availability is born out of a business need to provide guaranteed uptime to users and customers so the business is up and running when it is needed. As mission-critical solutions are carefully designed and developed, then deployed and managed, they mature. Constant changes to the mission-critical environment and ever increasing needs for uptime eventually will lead a business back to the beginning of the life cycle to refine and/or expand its goals for higher levels of availability.
HP's Mission-Critical Services Life Cycle (MCSLC) is a strategic framework that is linked with both the Pillars of Availability and the Availability Continuum. The Availability Continuum represents the requirement and the investments to achieve a given level of availability. By integrating the Pillars of Availability technology infrastructure, IT processes and support partnerships MCSLC provides a flexible, proven methodology to optimize availability and achieve a given availability requirement across the enterprise.
It can help customers determine their availability requirements, then implement and manage business systems and solutions to meet their needs across the systems life cycle.

There are four milestones in the evolution of a mission-critical environment.
Hewlett-Packard Company is firmly established as the leading supplier of mission-critical solutions in the open client/server marketplace today. Through its efforts to meet the availability requirements of customers worldwide, HP has created an expansive portfolio of mission-critical products and services. HP understands that mission-critical also means high reliability and performance.
Reinforcing its commitment to becoming the benchmark standard for mission-critical solutions by which the rest of the industry is measured, HP announced in early 1998 its mission-critical vision of "5nines:5minutes." HP's ultimate vision is to provide customers with 99.999% end user availability (or less than five minutes of downtime annually). HP intends to bring to market products and proactive services that will increase uptime of mission-critical IT applications across the entire environment, including hardware, operating system, database, application and network. The goal is to extend the concept of high availability from a component level to true end-to-end availability.
HP's mission-critical strategy is based on the following observations:
Technology infrastructure consists of highly available hardware and software that minimize the impact of a failure, the need for planned downtime and the time to diagnose and repair any outages. HP's technology infrastructure solutions include preventive features and failover capabilities built into the hardware or software that minimize planned downtime and provide diagnostics for HP-UX®, NT Servers and mixed UNIX/NT environments.
Preventive features, such as predictive software and self-healing technology, reduce the system failure rate and eliminate the risk of human error. These features and easy-to-use operations also can include patch tools (to proactively distribute, manage and track patches), as well as better testing of maximum configurations and targeted third-party solutions.
Failover capabilities minimize the impact of a failure with hardware and software resiliency. Planned downtime is reduced with online patching and online addition or replacement of disks, LAN, WAN and power supplies. Hardware diagnostics and software core dump analysis tools minimize the time to diagnose and repair problems.
Technology infrastructure is a strong foundation for the entire spectrum of HP products. HP 9000 Enterprise Servers are designed from the ground up to provide industry-leading levels of reliability. HP 9000 D-Class Enterprise Servers come standard with memory page deallocation and hot-plug internal disks to enable online replacement or addition of disks and integrated uninterruptible power supply (UPS). Like the larger K-, T- and V-Class Enterprise Servers, the D-Class also provides memory deallocation and automatic restart.
A broad spectrum of other products also enhance HP 9000 reliability. MC/ServiceGuard, HP's industry-leading, high availability software, protects network configuration and keeps mission-critical applications running. Today, there are more than 20,000 MC/ServiceGuard installations worldwide.
HP also enhanced its MC/LockManager software with Oracle's Parallel Server relational database product. This enhancement, which enables the clustering of eight HP 9000 servers, provides a robust, integrated solution for data integrity and application availability. Additionally, in some configurations, including EMC disk arrays, its failover capability provides protection for mission-critical applications on top of the HP-UX operating system.
Mission-critical IT processes are achieved through internal processes and proactive support contracts. These processes include the ability to manage and operate the computing environment as well as the proactive processes for performance management, configuration management and change management.
The objective of a mission-critical solution is to ensure that application availability to the end-user is not compromised by any changes. Operation should be non-intrusive. IT processes must integrate with major management frameworks and allow rolling upgrades to keep the system running 7x24x365.
IT processes, however, also must be defined, tested and measured to provide an organization with the ability to predict process performance over time. By measuring a process, IT can gauge performance and adjust the process prior to a failure. It also gives IT greater flexibility to meet changing service demands.
No process, however, stands alone. Defining and measuring any individual process must be done in the context of the entire mission-critical environment. It is mandatory to understand and define the interrelationships and dependencies between the target process and other processes across the enterprise.
The HP IT Service Management (ITSM) reference model is based on a set of industry standard concepts defined in the Information Technology Infrastructure Library (ITIL). The United Kingdom Government originally created this library to better understand the management of services delivered to the end-user community by IT professionals. Over the years, IT professionals and end-users have verified and refined ITIL principles. This model allows HP to assist customers to assess their current IT processes.
HP offers a broad continuum of services that enable customers to scale and manage their specific availability needs based on their computing environment. HP offers a range of mission-critical services, including Business Continuity Support and Critical Systems Support for UNIX and Windows NT.
HP's standard support includes software and network support, software licenses for new releases, patches, HP software updates, software media and documentation. It ranges from eight hours a day, five days a week to 24 hours a day, 365 days a year.
HP Business Continuity Support Services (BCS) is the industry's most comprehensive mission-critical support program. It features maximum onsite presence and an outage prevention program tailored to each customer's specific needs. This service is designed to identify and prevent problems before they can impact operations. If a problem should occur, the service can respond quickly to restore the system.
BCS features an assigned account team experienced in mission-critical hardware, software and network support. These specialists include an account support manager, trained specialists from HP's phone-in response center, R&D engineers, support delivery specialists and HP senior management.
The team begins by conducting an Operations Assessment of a company's operating environment to understand specific business needs. They identify precisely how to achieve the required level of system availability as well as areas of potential risk to maximize critical systems performance.
The Operations Assessment enables customers to understand what is required to achieve and sustain the system availability their particular business requires. It identifies IT operational strengths and weak links that affect system availability and then provides recommendations for implementing HP's proven best practices. By proactively identifying weaknesses, customers tend to experience fewer preventable problems.
BCS also provides daily reviews to determine which patches the customer needs to change. The account team is committed to the customer's service objectives, helping to plan changes and manage obstacles in the IT environment. The team has access to a regularly updated electronic profile of the customer's critical IT operations worldwide, 24 hours a day, seven days a week.
The emphasis of BCS is to keep the customer's mission-critical applications operating. It results in rapid response and recovery before paperwork; proactive management over a reactive crisis mode; and reduced business costs and outages.
HP Critical Systems Support (CSS) is a suite of services for businesses running enterprise-class computing environments that require very high systems availability. It is a modular, flexible service designed for companies that want a proactive response and immediate reactive support beyond HP's standard services.
CSS provides hardware, software and network support for critical systems that reduces the frequency of systems failures, and helps to recover systems when problems occur. As the first vendor to offer a six-hour hardware call-to-repair commitment, HP assigns a CSS support manager to lead a team of experts in maintaining mission-critical computing environments. These engineers provide guidance and assistance on technical and operational issues. The team's efforts result in fewer system problems, shorter planned downtime and a more effective use of technology.
In the event of an outage, the CSS system recovery team responds immediately. With access to HP's critical-parts network, personnel are dispatched immediately to repair system hardware within six hours. Phone-in software assistance is available 24 hours a day, 365 days a year.
The service scope of CSS includes an Operations Checkup. This is a high-level evaluation of the customer's needs, computing environment and mission-critical readiness that ranks risks against an industry model for availability. After comparing current mission-critical readiness against overall business needs, the Operations Checkup identifies outstanding risks and recommends actions to mitigate risks and improve uptime.
Critical Systems Support for Windows NT is a comprehensive, flexible solution that can augment technology and capabilities in the areas of administration, troubleshooting and managed change for NT Servers.
Fast and fully reactive software support services utilize the best engineers from HP and Microsoft Corporation to fix problems fast. Proactive account support and change management create a more stable operating environment when operating NT clusters to achieve mission-critical results.
The complement of five service modules implemented together, along with Operations Checkup and HP's hardware-call-to-repair commitment, provide a comprehensive NT solution that addresses fundamental causes of downtime in all the phases of an NT mission-critical solution life cycle. Customers can purchase these service modules individually to support specific needs today and then scale their solution as their NT usage increases.
Within its proactive, modular, mission-critical solutions (Business Continuity Support, Critical Systems Support for UNIX and Windows NT), HP offers a range of mission-critical services to help businesses minimize downtime and maximize IT availability.
In addition to these mission-critical services, HP's portfolio includes a variety of other services and tools to help businesses further maximize availability.
Just a few years ago, disaster recovery referred only to systems recovery within IT. Today, disaster recovery is more about strategies to stay in business, regardless of the event, and remain competitive. Businesses that once could work with a 48-hour outage, now cannot function with a two-hour interruption.
HP offers flexible recovery services to keep customers' businesses operating regardless of what interrupts their access to information. Since 1986, HP has provided recovery services worldwide to customers affected by actual disasters. HP also has assisted in hundreds of rehearsals. With access to 19 recovery centers located throughout the world, HP is only one of two vendors to offer complete worldwide recovery solutions. HP clearly has the experience, the resources and the organization to ensure business recovery in the shortest time possible.
To provide comprehensive business recovery solutions, HP has forged alliances with other recovery providers. These alliances give customers a single point of contact for contract administration, disaster declaration, resource coordination and even scheduling rehearsals.
Depending on a business' specific needs, HP can recover in a fully equipped and staffed HP hotsite facility or ship equipment and provide on-site expertise to a designated location, including a hotsite from another disaster recovery vendor.
HP's Mission-Critical Server Suite (MCSS) is a pre-configured, open systems solution that is designed to meet the stringent throughput and availability demands of business process re-engineering (BPR) and enterprise resource planning (ERP). Based on HP's industry-leading, scaleable family of HP 9000 Enterprise Business Servers, this suite packages the critical components for a mission-critical environment and offers an unprecedented 99.95% uptime (less than five hours of downtime annually). HP is in its second year of delivering MCSS and continues to develop enhancements as it moves toward its vision of 99.999% uptime (less than five minutes of downtime annually).
MCSS provides uptime commitment for maximum throughput with several HP technologies. These include:
HP facilitates implementation of MCSS with ongoing maintenance with the following tools and services:
Managing a network, even a small one, can be an extremely complex and costly undertaking. HP OpenView Professional Suite is a set of more than a dozen integrated network and system management applications to proactively control and administer heterogeneous networks. In short, it simplifies the management tasks and reduces the costs of supporting client/server computing.
At the heart of the HP OpenView Professional Suite is HP's Workgroup Node Manager. It creates a framework to access and use HP and third-party management applications. It also provides a single point of management and an integrated view of the network.
In addition to Workgroup Node Manager, the HP OpenView suite integrates over 12 other applications to manage the devices, applications and operating systems of the PC LAN. HP OpenView Server Management increases server availability through the use of predictive failure alerts. It also monitors and reports server access security breaches by unauthorized users.
Similarly, HP Network Device Management monitors network traffic between and among multiple devices. HP AdvanceStack determines realistic performance, availability and responsiveness goals for the network.
Recognizing the growing need to manage service levels over high-capacity, high-speed networks as well as the increasing need for Internet Service Providers (ISP) to grow their businesses, earlier this year HP expanded its HP OpenView portfolio with new products and technologies. The new HP OpenView Internet Service Manager is an integrated package that uses an integrated view to manage Internet services. It includes tools to manage web resource utilization, performance, link auditing and firewall monitoring. Internet Service Manager improves forecasting and facilitates response to unexpected system events in today's complex intranets.
HP OpenView Firehunter, a new comprehensive, Web-based solution, enables ISPs to monitor, measure and manage operations more efficiently. It allows for mission-critical service-based data to be collected from various systems within the ISP environment.
HP's High Availability Observatory (HAO) is a comprehensive set of support tools and processes targeted specifically for mission-critical support. Designed with a three-pronged approach to 'build it right,' 'keep it running' and 'fix it fast,' this suite of tools and processes serves two purposes. It provides proactive problem prevention services for systems that require maximum uptime; and it provides improved reactive services to reduce the time to fix problems should they occur.
HAO consists of four technology features: HP Support Node; Mission-Critical Support Center; HP Configuration Tracker; and HP Predictive Support/UX Failure Event Notification. Working in conjunction with the customer's computing environment, these tools collect configuration information, network topology and hardware fault indicators in a customer's mission-critical environment. Then "snapshots" of the information are transmitted to HP's Mission-Critical Support Center (MCSC) where the information is processed, analyzed and used by HP account support engineers to prevent potential problems. Notifications also are sent to HP support providers as well as to the customer.
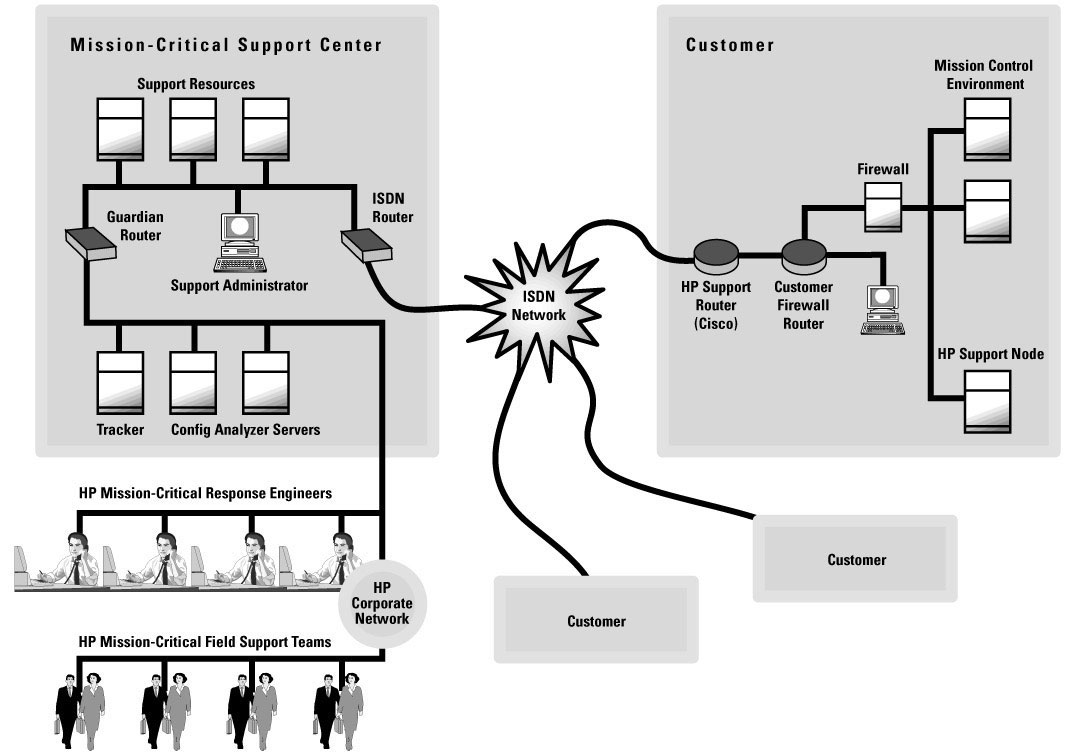
Both the HP Support Node and the MCSC are connected via ISDN lines
and appropriate routers (see Figure 6) within the HAO.
HP's HAO sets the industry standard for incorporating mission-critical technology to prevent problems before they occur.
While a single point of contact offers many advantages in manageability as well as cost efficiency, it is imperative that the single vendor be equipped to deal with any and all complexities of the mission-critical environment. HP has created strategic alliances with a variety of partners to provide customers with one-stop reporting and resolution. Some of these alliances are described below.
HP understands that the cost of sales is an important component for profit and loss. To keep profitability up and costs down, HP sells its products and services through multiple channels, both direct and indirect, using best-in-class partners.
When selecting a partner for mission-critical solutions, a company wants its vendor to know and fully understand the nature of its business. In its effort to meet the needs of its customers, HP offers industry-specific mission-critical services that go beyond its standard portfolio of services. For example, HP has expertise in mission-critical manufacturing services for ERP environments such as CSS for SAP R/3.
In another area, HP offers a set of discrete services tailored to the specific needs of its telecommunications customers. Specially trained Response Center engineers provide the unique training required for HP's telecommunications platforms and applications. For example, Response Center engineers are trained to assess current and future telecommunications environments before upgrades are performed. These engineers also can provided a detailed check-up of communication between platforms and the network.
Recognizing the growing demand for seamless network implementation and ongoing support, HP also provides mission-critical network services. These services involve partnerships with leading vendors for software release planning and software installation as well as industry-leading call-to-repair commitments. Together, Cisco Systems and HP network devices offer repair within six hours and remote reinstallation of network device configurations.
These network support solutions maximize network uptime and performance while ensuring that hardware problems will be resolved within a designated time frame. They also increase productivity of users and the network system manager.
HP's network availability services feature effective network troubleshooting, immediate on-site response for hardware problems, assigned personal contacts and remote network consulting. These services also include network availability review, software update and patch installation and rapid access to multi-vendor networking experts worldwide.
HP Engineering Services are clearly defined technical consulting services that provide short-term assistance for predetermined operations topics, such as change management, risk assessment or resource utilization.
These services are focused on reaching specific milestones as rapidly as possible. Beyond a more effective use of IT financial resources, HP Engineering Services also free up internal IT resources to work on strategic issues.
HP's Performance Resource Utilization (PRU) Module (which previously was only available as an option for BCS and CSS), as well as new services, including the Performance Optimization Module (POM), now are available as stand-alone services for UNIX or NT. They provide the customer with a comprehensive report on the performance of their system along with recommendations to improve it.
HP's Consulting Services can assist customers to achieve the highest possible application availability by providing a range of educational and implementation services. These services include IT Service Management, infrastructure planning and design services, security reviews, implementation services and education.
Based on the customer's specific mission-critical environment and needs, HP Consulting provides expertise on infrastructure processes needed to deliver service and manage information. These services can range from the assessment of current process weaknesses through the design, planning and implementation of a complete IT infrastructure.
Building an adaptable and evolving infrastructure requires skilled and knowledgeable professionals. HP Consulting offers a wide variety of educational courses that explore a broad range of issues affecting a mission-critical environment.
HP's Enterprise Desktop Management Services (EDMS) offers customers the flexibility to choose from a variety of services that can be applied to any part of the desktop life cycle. These services range from assessing readiness for desktop management through planning and building the environment to assisting with desktop management transition and distribution of software across the enterprise.
EDMS helps customers align their desktop systems with their specific business goals and respond to dynamic business requirements. These services reduce costs associated with desktop life cycle management and use business-critical applications in a client/server environment. EDMS enables customers to optimize their productivity and manage their desktop environment more efficiently.
HP is committed to the concept of "selective outsourcing." That is, HP works with its customers to help craft an outsourcing solution that complements customers' existing IT resources. HP is able to manage just those portions of the infrastructure that the customer wants a vendor to manage.
This, in turn, frees IT organizations to pursue other objectives that might be more strategic to the business or more relevant to the skills of the IT organization. It also helps IT organizations accelerate the rate of technological transformation, particularly in complex, mission-critical environments.
As a support partner, Hewlett-Packard Company offers the industry's best, most comprehensive services to meet mission-critical needs across the enterprise. In building its alliances, HP teams with its customers to understand their business and improve their particular computing environments. For companies requiring mission-critical services, HP's long-standing reputation and quality services and products offer a solid track record for gaining a return on investment.
HP's support services deliver value to every aspect of a customer's operation from service planning and management to infrastructure control and deployment, from operational processes to problem management and user support.
HP's dedicated management extends to 27,000 employees experienced in services and support who work from 60 customer education centers, six support technoloy labs, and 600 support offices in more than 120 countries. Globally, HP has the range, reach and reputation for enterprise-wide, mission-critical support in open, distributed computing.
Whether the customer's business is finance, manufacturing, telecommunications, retail or government, HP expects the pace to be fast and the competition to be stiff. There are numerous examples and positive results of HP's scalability, availability and disaster recovery all while conserving costs and resources. The following are just a few stories that demonstrate how HP's services and support can impact the bottom line.
On an average night, VISA settles over a billion dollars in purchases, checks or cash advances for the 15,000 banks that own the credit card company. If ever there existed a mission-critical environment, VISA is it.
Operating around the clock every day of the year, VISA requires 100 percent availability from the systems that daily process, settle and clear millions of transactions worldwide. Even a 15-minute outage can affect several hundred million dollars worth of processed transactions.
VISA's top three priorities for improving availability are: commonality of systems and services; control; and stability. The confidential nature of its business demands secure transactions, which require total control. VISA also requires a stable, trustworthy operating system on which it can fall back, if necessary.
VISA is gradually moving from IBM mainframes to client/server networks to reduce costs and achieve better scalability. It currently uses a mainframe as well as 12 HP 9000 Enterprise Servers: four K/460s; five K/520s; and several Series 700 workstations; and HP's Business Continuity Support.
Jim Long, director of application development at VISA's San Mateo, Calif. data center, cites the SMP architecture of the K-Class Enterprise Servers as a real advantage of HP. "We value HP for its capacity planning and its performance tuning. Nothing else is quite as reliable. HP came in first as a UNIX box."
To ensure mission-critical availability for its client/server networks, VISA contracted with HP to provide the maximum level of support. This service is designed to identify and prevent problems before they impact business operations.
"We also appreciate the way HP takes an interest in our business," added Long. "We need a partner who really tries to understand our particular needs and who will answer questions in our environment. This helps VISA sustain our growth and stay number one."
As one of the top five auto insurers in California, Mercury Insurance Group of Los Angeles faced rapid growth as it branched out nationally. With over a billion dollars in annual revenue, the 30-year old company relied heavily on its information system.
An HP customer since 1986, Mercury had 12 HP 3000s that supported its underwriting and claims business. Over 2,500 employees and 1,000 independent agents constantly accessed this mission-critical system. Despite the severe strain on its system, the insurance company's IT group tried to respond to the growing volume of business. However, frequent upgrades and downtime during system expansions began to take a toll on system availability and operating efficiency.
Jerry Pham, Mercury's computer operation manager, explained, "We needed to have the system online at all times. I didn't have any leeway to have the system down."
To ensure mission-critical computing, Mercury chose HP's Critical Systems Support (CSS). It guaranteed a fast response, technical expertise and single-vendor coordination.
"We decided that we just couldn't take the risk of insuring our systems with someone other than HP," Pham said.
The results speak for themselves. With CSS, uptime for Mercury's entire mission-critical computing environment improved to 99.9% from 40%. Pham admitted, "Before, I couldn't even maintain that (level of uptime) for one system." He is quick to attribute this increase to HP's proactive support and responsiveness.
The increase in availability led to another positive result for Mercury. Because information is available immediately, agents can provide better service to their customers.
Merisel, Inc., a leading distributor of computer hardware and software products based in El Segundo, Calif., distributes a full line of 25,000 products to more than 45,000 resellers through North America. With reported annual sales of $5.5 billion, Merisel has stringent service level requirements with sub-second response time. Such requirements place tremendous demands on the company's hardware technology to provide greater and greater throughput capabilities.
Merisel has a variety of different systems and technology: client/server Sybase systems, client/server Oracle systems, mainframe systems as well as server technology running in-house LAN-based applications. The company is currently converting from its legacy mainframe systems to HP 9000 T/520s and K/420s running an SAP R/3 environment. This conversion will allow Merisel to facilitate a North American strategy and will improve the accuracy, accessibility and availability of information.
Merisel actually has been operating the HP/SAP environment in Canada since 1995. It has four HP 9000 Series K/220 servers and an HP Mission-Critical Services and Support contract that supports over 400 users. In this environment, the response time averages between 0.6 and 0.7 seconds. Merisel's performance monitoring proves that 90% of all transactions are less than one second; and 99.5% are less than 10 seconds. These transactions are based on an average of 450,000 calls per day. The U.S. operation anticipates four times this number of dialogs.
Mary West, Merisel vice president of information systems, commented, "HP and SAP certainly have given us a lot of advantages. Between the IS organization and the business community, there is a service level expectation. The expectation is that you must be able to process orders at all times and never have any downtime."
She confided, "We know when our competitors' systems are down because our order volume increases dramatically and vice versa! It is absolutely critical we have back-up order entry and mission-critical operations because we literally cannot afford downtime."
According to West, Merisel uses numerous tools from HP to proactively manage its systems (Network Node Manager, GlancePlus and PerfView). "We're very oriented to preventive action, but if we have a problem, we can recover quickly with our support processes and products like MC/ServiceGuard and EMC Symmetrics. HP is able to give us the service that we need."
The ever-expanding need for increased application availability exposes IT to greater vulnerability and additional potential areas of exposure and failure. Businesses must determine their optimum service strategy and availability levels across their IT environments to ensure maximum uptime for mission-critical applications. Businesses cannot afford to operate without mission-critical services.
When it comes to managing a mission-critical IT environment, availability undeniably is a critical success factor. However, reliable technology alone cannot substitute for strong support services and integrated management. All three must come together as a total solution.
Because each environment is unique, there is no single right combination to create mission-critical computing except with Hewlett-Packard Company. As one of the world's most respected computer companies, HP has been lauded consistently by Fortune Magazine for its high level of quality services, financial stability and value. HP is recognized world wide not only for its superior products, but also for its leadership and technical strength. Consider HP's track record for service and support as ranked by these publications.
HP works with its customers to select the right partner to help make technology choices. Then it can help customers capitalize on the value of their technology investments in availability. Finally, HP can help maximize customers' current investment in people, infrastructure and partnerships.
Today, HP offers an industry-leading 99.95% uptime commitment (less than five hours of downtime annually). But this is only a beginning. In the near future, HP's vision of "5nines:5minutes" will become the standard requirement of 99.999% (less than five minutes of downtime annually).
HP knows how to optimize the mission-critical computing environment for UNIX and NT. HP is available to help companies plan and deploy the latest technology trends across their mission-critical life cycle to achieve unprecedented levels of availability. Drawing on its own experience and the strength of its partners, HP has the reach, the reputation and the resources to give its customers every competitive advantage.