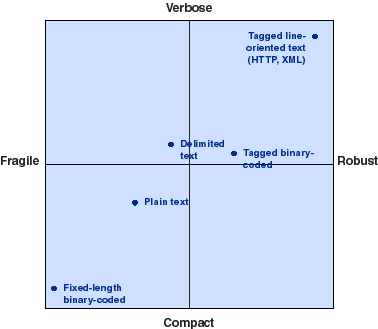
Figure 1. Protocol design space
The client/server application architecture has become a standard design pattern, and for good reason. It splits the complexity of the application into more manageable pieces, and when implemented over a network or other communication channel, can split the processing load as well. Particularly for applications which require a sophisticated user interface, a client/server architecture can save substantial implementation time over a monolithic design.
Implicit in a client/server architecture is a method for communicating between the client and the server. The method includes a physical component -- anything from shared memory to a serial connection -- as well as a protocol component. This paper discusses the design of protocols for communicating between parts of an application, assuming the existence of a physical communication medium. The design space is analyzed first, and then several protocols are proposed to fit different locations in the design space.
Any sizeable software design involves design tradeoffs among objectives that cannot be achieved simultaneously. Communication protocols have two key characteristics, which are often at odds with each other:
Clearly, there are other factors involved, such as ease of implementation. However, these factors affect only the implementation stage and have very little effect over the useful life of the application.
In general, achieving robustness implies adding some redundancy to the information to be communicated, and adding overhead such as checksums, error correction, or checkpoint marks. This increases the total number of bits transmitted. Figure 1 illustrates placement of protocol designs in this space.
Figure 1. Protocol design space
The choice of a point within this design space is based on the characteristics of the expected communication channel. Some channels, for example shared memory, have very high bandwidth and are very robust. Such a channel places few demands on the communication protocol. By contrast, if the communication channel is a slow modem without error correction, the protocol must be robust enough to operate through a high error rate, yet use a minimum number of bits. Typical Internet connections fall somewhere between these two extremes.
One important consideration that is sometimes overlooked when analyzing the reliability of a communication channel is the ability to detect truncated transmissions. While Internet protocols, and many of the lower-level transport protocols on which they rely (e.g., ATM, Ethernet) offer reasonable guarantees that data sent will arrive intact if it arrives at all, there is no automatic protection against breaks in the channel. Application protocols must be designed to detect truncated transmissions that may result from channel failure.
Other channel considerations include whether the path is capable of supporting arbitrary binary transfers, and whether the channel offers a simple stream path or a record transfer service. Since a stream service can emulate a record service and vice versa, this consideration can be eliminated with a small amount of work.
In a client-server communication protocol, clients typically make requests, which are then responded to by the server. In the simplest protocol implementations, this is an exact description of the interaction.
Client Server
---------------------- ------------------------
Login -->
<-- Login accepted
Query -->
<-- Return records |
A more robust protocol will sometimes separate the response to the request from an acknowledgement of it. This is particularly useful if processing the request can take a long or unpredictable amount of time. For example, if a client requests a database query, the server can acknowledge the query after checking it for validity, possibly compute an estimate of the amount of time the query is expected to take, and send that back to the client as an acknowledgement. The server then performs the database query and eventually sends back the response.
Client Server
---------------------- ------------------------
Login -->
<-- Login accepted
Query -->
<-- Return count and ack
(later)
<-- Return records |
Separating the acknowledgement from the response improves robustness by providing some insurance against communication failure. It also improves the user experience by providing immediate feedback for the user's request. In the limit, both the client and the server can accept input asynchronously, providing many opportunities to keep the user informed of what's happening with his/her requests. Such a design offers other advantages as well, and as with compactness and robustness, a range of implementations is possible.
This design axis for a communication protocol ranges from master-slave at one end to peer-to-peer at the other. In a master-slave protocol, the server responds to client requests with a single response, and never initiates a transaction on its own. In a peer-to-peer protocol, either endpoint may initiate communication.
A stateless protocol such as Hypertext Transfer Protocol (HTTP) must always be master-slave, for the simple reason that the server doesn't know about the existence of a client until the client communicates with it, and then forgets about the client immediately afterward. Master-slave protocols are simple to implement, because each endpoint can either sending or receiving but not both at any given time. Standard mainframe programming techniques, involving waited I/O, are all that is required to implement either a master or a slave.
Peer-to-peer protocols are considerably more difficult to implement, particularly in a mainframe environment. Each endpoint must be prepared to receive either requests or responses at any time. This is quite difficult to do in a traditional mainframe environment, and some care must be used when trying to emulate a peer-to-peer relationship in a waited I/O environment.
The advantage of a peer-to-peer architecture is that the application can appear much more responsive. Even a small amount of additional work can result in substantial benefits. For example, if the server can check periodically for cancellation requests from the client while it is performing a lengthy operation, the client's user will never lose control of the application.
Client Server
---------------------- ------------------------
Login -->
<-- Login accepted
Query -->
<-- Return count and ack
(server working)
Cancel -->
<-- Cancelled |
A system such as this can be implemented on any server that supports a look-ahead or non-destructive read feature on the I/O channel. Most network implementations provide this, though such a scheme is problematic using standard MPE/iX terminal I/O.
Similarly, if the client can be prepared to accept messages from the server asynchronously, the server can inform the client of exceptional conditions -- for example, the server can transmit system status messages to the client, allowing the user to keep track of system load conditions or be notified of an impending system shutdown.
Client Server
---------------------- ------------------------
Login -->
<-- Login accepted
Query -->
<-- Return count and ack
(server working)
<-- "1000 patients processed"
<-- "2000 patients processed"
<-- "Operator: system going down now!"
<-- "3000 patients processed"
Cancel -->
<-- Cancelled |
Clearly, this implies a sophisticated architecture for the server, with the ability for the server to multiplex messages from many different sources to the client, and -- usually -- the ability to dispatch different kinds of client messages to different parts of the server.
Perhaps the simplest possible protocol is a fixed-length transfer in which both sender and receiver agree on the positions of data fields within the fixed-length transfer. Figure 2 illustrates a common and well-worn use for such a protocol.
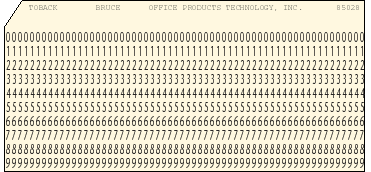
Figure 2. Simple fixed-field protocol
Clearly, ignoring blanks (which may or may not need to be preserved), this protocol is about as compact as possible without using data compression techniques. There is no overhead because both the sender and receiver have agreed on all of the communication parameters in advance. Conversely, this protocol provides almost no protection against communication channel data loss or version mismatches. It is also, in many environments, trivial to implement.
A protocol such as this is well-suited to in-memory data transfer between closely-synchronized clients and servers. However, there is no protection against version mismatches, and none against communication channel drops. While these disadvantages may seem obvious, this protocol was recently proposed by a large organization as the basis for a national data interchange network.
A fixed-length, fixed-record protocol can be improved with a small number of changes. First, a header record can be prepended to the transmission, stating the total expected length of the transmission and giving a version number. The receiver can then check the version number to make sure it can understand the transmission, and can use the length as a check against communication channel failure.
Many standard high-level Internet protocols are text-based. This has several advantages. Text-based protocols aren't sensitive to whether a channel can handle arbitrary binary data. They are easy to develop and to debug. They can be robust against channel failure, because resynchronization after a communication failure can be no more complex than waiting for an end-of-record character. A text protocol can also be made robust against version mismatches, a particularly important characteristic in a chaotic software environment like the public Internet.
Often, transactions in these protocols look exactly like what an observer would expect in a dialog between a computer and a person at a terminal. In fact, most Internet text-based protocols are based on Telnet, the Internet terminal-to-host protocol. This makes it easy to use a terminal emulation program to test a server in the early stages of its construction.
A good illustration of the advantages and disadvantages of text-based protocols is Simple Mail Transfer Protocol (SMTP), the universal electronic mail exchange protocol used on the Internet.
Client Server
--------------------------- ------------------------
HELO landru.optc.com -->
<-- 250 newlandru.optc.com
MAIL FROM: toback4@optc.com -->
<-- 250 OK
RCPT TO: toback3@optc.com -->
<-- 250 OK
RCPT TO: billgates@optc.com -->
<-- 550 No such user here
DATA -->
<-- 354 Start mail input
Blah, blah, blah... -->
Blah, blah. -->
-->
-->
<-- 250 Message accepted
QUIT -->
<-- 221 Closing connection
|
This is clearly just a simple terminal exchange; in fact, the client could be a (very patient and accurate) person sitting at a terminal. Requests contain a distinctive four-character header followed by additional information about the transaction. Requests are terminated by end-of-record characters (carriage returns and/or line feeds), so both parties can find the ends of commands and acknowledgements. As a result, this protocol can only exchange printable characters, since binary data may contain end-of-record characters. In addition, any DATA to be exchanged can't contain two or more blank records, since the server would interpret this as the end of the message. (The protocol must therefore either re-encapsulate any message that contains two or more blank lines, or alternatively eliminate the blank lines. Obviously, having the protocol modify the data that it's being used to encapsulate has serious disadvantages.)
Such protocols contain comparatively little overhead, and are very easy to implement. They are moderately robust against version changes as long as client and server agree on what to do when a command isn't recognized. Taking advantage of this also requires implementing a new command whenever the data associated with that command changes between versions.
Simple text-based protocols are adequate for a variety of applications. They are particularly adaptable to situations where data entered by the user is simply being encapsulated and sent to the server without any interpretation. If the data to be exchanged consists of distinct fields, it is possible to separate the fields either by a character that won't appear in the data. If the application can't predict the data character set in advance, it can scan each field and replace instances of the delimiter with an escape character of some sort (which must in turn be escaped.)
Binary transfer protocols can provide additional versatility and robustness against version changes, at the cost of being less robust against communication channel failure. In a binary protocol, small fixed-length binary fields are exchanged and used to encapsulate application data appropriately.
A tagged protocol tags each data element with a unique code. This permits the receiver to parse the message unambiguously, even when an element isn't recognized. While tagged protocols can be used in an all-text environment, a pure-text enviromnent loses the advantage of being able to encapsulate arbitrary application data, regardless of whether it is text or binary.
One particular concern when using binary protocols is the order in which bytes are stored. The Internet has a defined byte order which states that the most significant bits are to be transmitted first. Computers made by Compaq (formerly Digital Equipment Corporation), Intel and others store binary data with the least-significant byte first. In general, it is preferable to use network byte order for all data exchanged across a network. The small amount of time spent in reversing byte order for systems that require it is outweighed by eliminating problems caused by uncertainty about the byte order.
Figure 3 illustrates a tagged transaction. A basic transaction consists of nothing more than an overall length, a transaction code, and a tag count. Even the overall length is redundant in this case, since a receiver could use the fixed-length transaction header to calculate the expected position of all other transaction data.
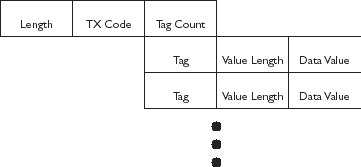
Figure 3. Tagged Transaction Layout
Each tag is a fixed-length binary value, an element in a dictionary known to both endpoints. The data length gives the length of the value associated with each tag. This length is specified even in cases where the implied data type of a tag already specifies the length. This characteristic allows a receiver which does not understand a tag to skip over it without losing its place in the data stream.
Such a scheme is very robust against version changes, because older versions of software can ignore data that is supplied but not understood. This requires careful transaction design, of course, since the transaction must still make sense even without some new parameter added later. If it does not, then a new transaction code should be implemented. Again, this won't impact the ability of the receiver to process the old transaction code.
The use of binary data, and in particular binary lengths, means that if the communication channel drops or garbles data, the receiver and sender will probably lose synchronization permanently. The protocol provides no anchors, such as end-of-line markers, on which a receiver could resynchronize. Thus, a binary tagged transaction scheme should be implemented only over a reliable communications channel.
The design of custom client-server protocols involves a several key design trade-offs. Choosing an optimum transaction design requires careful analysis of both the data to be exchanged and the characteristics of the underlying transport protocol. No single protocol will provide the optimum user experience in all cases, but project goals and user expectations can provide considerable guidance in making a good long-term choice.